 Java 學習之路
Java 學習之路 photo credit: bertboerland via photopin cc
photo credit: bertboerland via photopin cc
MySQL 資料複製基礎介紹
|
現今的資訊系統,資料常常是系統中最有價值的東西,更是不容許有任何的閃失造成資料遺失。同時,資訊爆炸的時代,資料量往往造就了一個龐大的怪物,令應用程式將整個系統資源吃光。 所以,如何從資料的角度來改善應用系統,就變成資料庫管理中,最重要的課題。解決資料問題的方法有很多種,這次我要介紹的是利用MySQL的資料複製(Replication)來解決資料的問題。 首先要介紹關於資料複製的專有名詞: 1. 主伺服器(Master Server):
2. 從伺服器(Slave Server):
3. 二進位日誌檔(Binary Log):
4. 同步資料複製(Synchronous Replication):
5. 非同步資料複製(Asynchronous Replication):
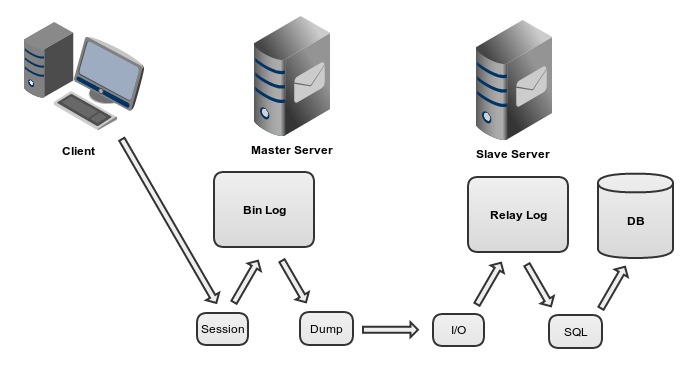
再來要介紹的是,MySQL資料複製可帶來的好處: 1. 建立系統的高可用度: 因為有多個MySQL伺服器,所以建立了錯誤轉移(Fail-over)的可能性,而成為高可用度的資料庫。 2. 建立系統的可擴充性: 可以從MySQL資料複製中,建立多個從伺服器。所以在需要增加資料庫的查詢效能下,可藉由增加從伺服器的角度來擴充MySQL資料庫系統。 3. 離線資料處理: 在從伺服器中作離線查詢,則不會干擾而影響主伺服器的效能。單純使用從伺服器來產生報表。 常見的資料複製架構有: 1. 主-從資料複製。 這樣一對一的複製架構,可用來作異地備援,避免因意外造成資料丟失。 2. 一主-多從資料複製。 這樣一對多的複製架構,使用者可以用多個從伺服器來分散資料的讀取負載,也讓使用者可以輕易的延展(Scale-Out)從伺服器進而提昇讀取效能。但新增/修改/刪除交易,還是由主伺服器負責,也引此,這樣的架構,較適合用在查詢負載較重的OLAP系統。 3. 主-主資料複製。 這是建構MySQL複製中最常見的架構。這兩台伺服器都可以讀/寫,且互為備援。在應用程式的支援下(自動切換資料庫連線),可以達成高用度的系統。 4. 多主資料複製。 相較於”一主-多從”與”主-主”的資料複製架構,多主資料複製可以在提昇效能的前提下,又達到高可用度的目的。 但受限於MySQL的資料複製架構,一個從伺服器只能接受單一個主伺服器的資料。所以,在架設多主資料複製時,只能用”環形”的方式作資料連線。換言之,但有一台伺服器故障,整個環狀結構的斷掉,此時,需要將故障的伺服器從架構中剔除,重新建立一個新的多主資料複製的環狀結構。 資料複製的流程圖(略圖):
在這個流程圖中,並沒有將全部的步驟都繪畫出來,只針對主要的流程加以說明(例如,這個圖就沒有畫出,當從伺服器中的SQL程序將資料輸入資料庫時,也會將資料寫入Bin Log)。讓我們來走過一次流程吧! 1. 當用戶端連線到資料庫時,資料庫即建立一個session。當資料從session將資料輸入到資料庫中,則資料庫會將收到的事件(insert/update/delete)紀錄一份到Bin Log。 2. 從伺服器的I/O執行緒會定期跟主伺服器的Dump執行緒要資料,而主伺服器的Dump執行緒會將資料傳給從伺服器的I/O執行緒,並由I/O執行緒將資料傳入到從伺服器的Relay Log。 3. SQL執行緒會將資料從Relay Log取出,並輸入到本機的資料庫中。 接下來要介紹,資料複製的基本設定方式。 假設你已經有一台MySQL伺服器,現在要多加一台MySQL伺服器,同時要把他架成主-從資料複製,其步驟如下: 1. 修改主/從伺服器的my.cnf設定檔。 主伺服器: [mysqld] ... server-id=1 log-bin=/xxx/log/master-bin 從伺服器: [mysqld] ... server-id=2 2. 在主伺服氣上建立帳號並授與複製權限。 例如… master> CREATE USER 'replicator'@'slave_host'; master> GRANT REPLICATION SLAVE on *.* to 'replicator'@'slave_host' IDENTIFIED BY 'replicator_password'; 3. 在主伺服器上備份資料。 備份的方式有分冷/溫/熱備份,就依讀者的環境自行決擇吧! 4. 在從伺服氣上作資料回復。 將步驟三所得到的備份檔案,在從伺服器上作資料回復。 5. 在從伺服器上建立資料複製的設定。 例如… slave> CHANGE MASTER TO -> MASTER_HOST = 'master_host', -> MASTER_PORT = 3306, -> MASTER_USER = 'replicator', -> MASTER_PASSWORD = 'replicator_password'; 6. 啟動從伺服器,進行資料複製。 slave> START SLAVE; 再來要介紹如何回復資料複製的程序。 有時後會遇到,MySQL伺服器錯誤,導致資料不再由主伺服器複製到從伺服器。此時,就需要作回復資料複製的操作。在作災難回復時,所需要的東西與步驟如下: 需要的東西:
執行的三個步驟:
例如… mysqlbinlog -- start-position=position --stop-datetime=datetime master-bin.000001 master-bin.000002 … | mysql -u root -p 4. 重新設定資料複製。 例如… slave> CHANGE MASTER TO -> ... -> MASTER_LOG_FILE = 'master-bin.000010' -> MASTER_LOG_POS = '123456'; 結論: MySQL複製(Replication),是一個簡單就可以達成延展(Scale-Out),高可用度的架構。因此,也被企業使用。但是,複製是屬於非同步的資料複製,所以還是可能會因為時間差而造成資料不一致的現象(最終還是會完成同步,資料一致)。如果,讀者有即時的資料查詢/更新的需求,那可能還是需要MySQL Cluster的架構才能符合需求。 |
相關文章
關於作者




曾任昇陽電腦教育訓練中心講師,授課範圍有Solaris / MySQL / Perl ... 等,對IT技術的興趣很廣泛,尤其熱衷在研究開源的技術。
王慕羣
07/01建議主從改為master-slave,用英文比較容易精準表達出來。