 Java 學習之路
Java 學習之路
Java EE 7 – Batch Applications for the Java Platform(二)
|
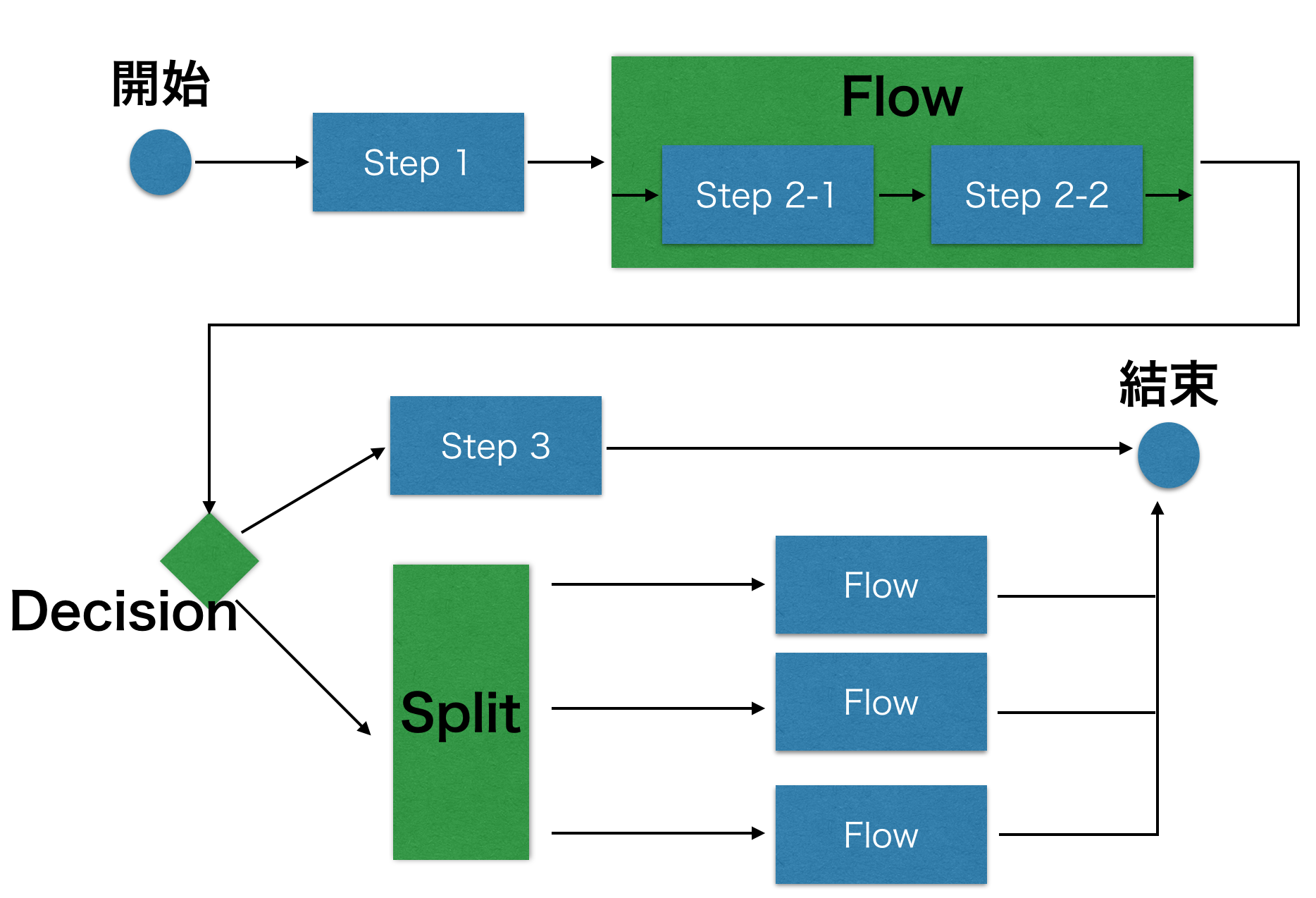
Java EE 7 – Batch Applications for the Java Platform(一) << 前情 前言本次連載爲 Java EE 批次處理四個主要功能中的「流程控制」、「Checkpoint」做進一步介紹。 流程控制在上一次的介紹中有提過流程控制的幾個元件,Flow、Split 和 Decision:
先將上一次介紹的範例再加上一個 step,將輸出的結果上傳到遠端的主機上。這次不使用 Chunk Oriented Processing 方式,而是改採用 Batch 方式來實作上傳部分。 job 的設定部分就會像以下範例,先完成計算( compute )後的下一步就是上傳檔案( upload )。 <?xml version="1.0" encoding="UTF-8"?>
<job id="simplejob" xmlns="http://xmlns.jcp.org/xml/ns/javaee"version="1.0">
<step id="compute" next="upload">
<chunk>
<reader ref="simpleJobReader"/>
<processor ref="simpleJobProcessor"/>
<writer ref="simpleJobWriter"/>
</chunk>
</step>
<step id="upload">
<batchlet ref="uploader" />
</step>
</job>
Batch 跟 Chunk 不同在於,Chunk 適合在需要一筆一筆處理資料時使用,例如讀取檔案或資料庫中的資料,並且可以逐一處理內容時;而 Batch 則適用於非資料筆數相關,需要長時間執行的動作,例如執行作業系統的命令,(解)壓縮或是上下傳檔案。以下為本次用於上傳的範例,使用Apache HttpComponents 來完成上傳檔案的 Http Form 的網站。Batch 常用在長時間的不可分割行為上,所以繼承 AbstractBatchlet 後只有一個最重要的 process 方法需要實作。最後回傳的字串主要是要決定整個處理的狀態,在這邊先不管是否上傳成功,都回 COMPLETED 來當作正確完成。 @Named
@Dependent
public class Uploader extends AbstractBatchlet {
@Override
public String process() throws Exception {
Response response = Request.Post("http://localhost:8080/sample")
.body(MultipartEntityBuilder.create()
.addBinaryBody("result", new File("/tmp/output.txt"))
.build())
.execute();
return "COMPLETED";
}
}
所以有多個動作要執行時,就像上面 job xml 的設定只要一個接著一個就可以。 Flow在這邊如果將上述的兩個 step 合併成一個單位,那就需要使用 flow 來達成,例如下面這樣。 <?xml version="1.0" encoding="UTF-8"?>
<job id="simplejob" xmlns="http://xmlns.jcp.org/xml/ns/javaee"version="1.0">
<flow id="computeFlow" next="step2">
<step id="compute" next="upload">
<chunk>
<reader ref="simpleJobReader"/>
<processor ref="simpleJobProcessor"/>
<writer ref="simpleJobWriter"/>
</chunk>
</step>
<step id="upload">
<batchlet ref="uploader" />
</step>
</flow>
<step id="step2"...</step>
<flow id="flow2"...</flow>
</job>
flow 跟 step 一樣可以設定 next 指定下一個行為,另外 flow 下面除了可以放入 step 以外,還可以放同樣是 flow ,以及之後會介紹到的 split 和 decision。 Split當有複數 flow 可以同時執行時,可以使用 split 將多個 flow 整理在一起。例如在處理資料完畢後,需要將資料用不同協定傳到多個不同的主機。 <?xml version="1.0" encoding="UTF-8"?>
<job id="simplejob" xmlns="http://xmlns.jcp.org/xml/ns/javaee"version="1.0">
<step id="step1"...</step>
<split id="split1" next="step2">
<flow id="flow1">
<step id="uploadToA">
<batchlet ref="upload1"/>
</step>
</flow>
<flow id="flow2">
<step id="uploadToB">
<batchlet ref="upload2"/>
</step>
</flow>
</split>
<step id="step2"...</step>
</job>
執行環境便會依照 split 的設定並行執行,因此像上面的範例便會同時執行 uploadToA 和 uploadToB 兩個工作,當 split 下的工作都完成以後便會執行下一個設定的工作。以上範例可以了解,split 本身並不困難,只要將可以同時執行的行為放在 split 下就可以了。 Decision關於流程控制,規格中定義了 next, fail, end 和 stop 四種元件,這四種元件都有一個屬性 on,當收到 on 所指定的狀態字串( exit status )時便執行定義的行為。next 設定要導到的下一步(例如 step );fail 將整個 job 設定為 FAILED 並結束;end 將整個 job 設定為 COMPLETED 並結束;stop比較特別是除了將整個 job 設定為 STOPPED 並結束外,還另外必須設定 restart 屬性,當 job 重啟時會依照 restart 所設定的單位( step, flow, split )開始執行。 以上四種元件放在 step, split 和 flow 之下,並依照執行結果做流程控制。下面是一個 step 下設定流程的範例。在 chunk 過程中如果結果為 status1 那麼接著就會到 step2 執行,而如果是 status2 和 status3 則是結束並設定 job 的狀態為 FAILED 或是 STOPPED。 <?xml version="1.0" encoding="UTF-8"?>
<job id="simplejob" xmlns="http://xmlns.jcp.org/xml/ns/javaee"version="1.0">
<step id="step1" >
<chunk>
<reader ref="simpleJobReader"/>
<processor ref="simpleJobProcessor"/>
<writer ref="simpleJobWriter"/>
</chunk>
<next on="status1" to="step2"/>
<fail on="status2"/>
<end on="status3"/>
</step>
<step id="step2"...</step>
</job>
Batchlet 的 process 方法可以直接回傳狀態字串,而如果是用 Chunk 的方式來設計,那麼就得將 StepContext 注入到對應的 reader, processor 或 writer 後,依照狀況使用 setExitStatus 來設定狀態字串。 @Named
@Dependent
public class SimpleJobReader extends AbstractItemReader {
@Inject StepContext stepContext;
@Override public Object readItem() throws Exception {
...
if(...) {
stepContext.setExitStatus("fail");
....
}
....
}
}
除了上面這種方式外,另一個方式就是獨立出一個 Decider 來判斷。Decider 的 decide 方法會取得來源的執行結果,因此可以透過這些結果來控制流程。以下為 job xml 設定和程式示意,當來源的 step 的狀態為 FAILED 時便會回傳 status2 ,因此整個 job 會停下並設定為 COMPLETED。 <?xml version="1.0" encoding="UTF-8"?>
<job id="simplejob" xmlns="http://xmlns.jcp.org/xml/ns/javaee"version="1.0">
<step id="step1" next="decider"...</step>
<decision id="decider" ref="decider">
<next on="status1" to="step2"/>
<fail on="status2"/>
<end on="status3" />
<stop on="status4" restart="step2"/>
</decision>
<step id="step2"...</step>
</job>
@Named
@Dependent
public class Decider1 implements Decider {
@Override public String decide(StepExecution[] executions) throws Exception {
...
if(executions[0].getExitStatus().equals("FAILED")) {
return "status2";
}
....
return "status1";
}
}
Checkpoint在上一次的介紹中有大略提過Checkpoint:
Chunk 的 ItemReader 和 ItemWriter 有 checkpointInfo 方法讓我們回傳相關資訊,每當 Chunk 完成時便呼叫 checkpointInfo 方法,然後在 open 時會傳入記錄的 checkpoint。。預設每 Chunk 的筆數為10筆,如果想要修改可以改變 job xml 中 chunk 的 item-count 屬性就可以了。 <?xml version="1.0" encoding="UTF-8"?>
<job id="simplejob" xmlns="http://xmlns.jcp.org/xml/ns/javaee"version="1.0">
<step id="step1" >
<chunk item-count="10">
...
</chunk>
</step>
</job>
以下為一個簡單的記錄 Checkpoint 和重新執行後,從指定筆數開始讀取。 @Named
@Dependent public class SimpleJobReader extends AbstractItemReader {
private BufferedReader inputReader;
private int count;
@Override public void open(Serializable checkpoint) throws Exception {
inputReader = new BufferedReader(new FileReader("/tmp/input.txt"));
if(checkpoint == null){
return;
}
count = (int) checkpoint;
for(int i = 0; i < count; ++i){
inputReader.readLine();
}
}
@Override public void close() throws Exception {
inputReader.close();
}
@Override public Object readItem() throws Exception {
String line = inputReader.readLine();
if(line == null) {
return null;
}
count++;
String[] fields = line.split(",");
return fields[1];
}
@Override public Serializable checkpointInfo() throws Exception {
return count;
}
}
Checkpoint 的設定除了上述的 item-count 以外,也有另一種方式來設定是否該設定 checkpoint。將 job xml 中 chunk 的 checkpoint-policy 設定為 custom,並新增一個實作 CheckpointAlgorithm 的類別和對應的設定來達到複雜一點的 checkpoint 判斷。 結尾本次稍微再詳細說明了 JSR-352 的其中兩個主要功能,下一次將會對 Batch 剩下的兩個重要功能做介紹。 後續 >> Java EE 7 – Batch Applications for the Java Platform(三) |
相關文章
關於作者

愛好 Java 的工程師,前幾年主要開發 Web Application,最近則在接觸 Mobile App 開發。
j4tony
09/25請問一下,在Decision 節的 Decider段落下面的xml範例。範列中decision node 的 屬性ref 值是否為decider class 名稱呢?