 Java 學習之路
Java 學習之路
Hadoop as a Service(2)在 HDInsight Cluster 執行 MapReduce 程式
|
在第一篇文章「Hadoop as a Service(1)雲端時代的 Hadoop Cluster 環境建置」,我們把 HDInsight 當作是一個雲端非常方便佈建的 Hadoop Cluster 來看待,所以標題稱為 Hadoop as a Service。建構好 Hadoop Cluster 之後,我們在第二篇文章,就要真的把現有的 Hadoop 應用程式拿來執行,看看是不是真的可以把 HDInsight 真的當成一個 Hadoop 來看待。 重建 HDInsight Cluster因為 HDInsight Cluster 希望提供的是一種 On-Demand 型態的服務,也就是有需要的時候就建立、用完就砍、隨時有需要就重練,所以請先按照上一篇文章的作法,建構一個 HDInsight Cluster,Data Node 只要一個就夠了。為了方便解釋起見,相關名稱就沿用第一篇文章內使用過的名稱,方便大家對照著操作:
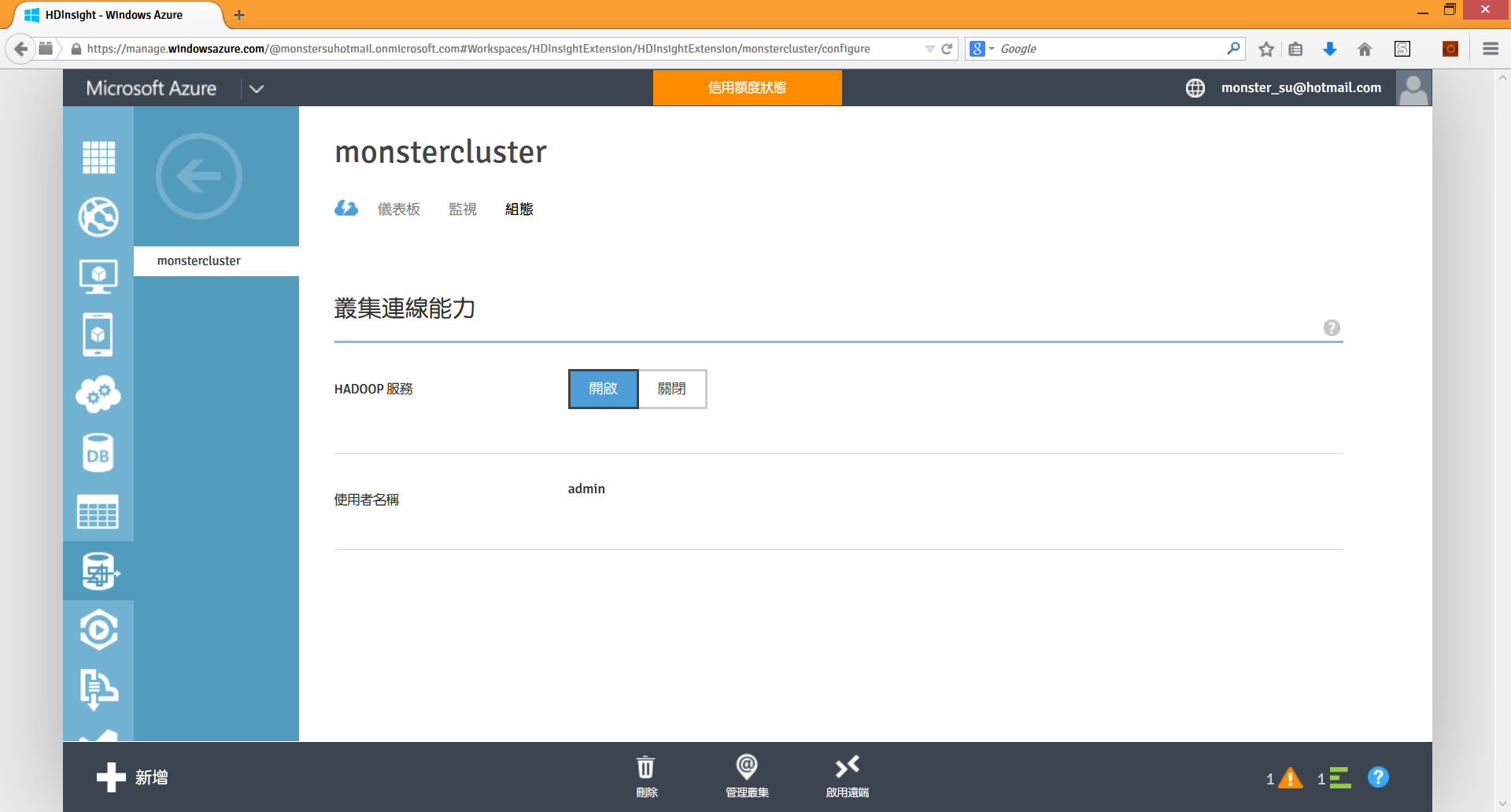
啟用遠端桌面連線HDInsight Cluster 的遠端桌面連線功能,預設是關閉的,因為雲端上頭駭客多,多開個 Port 就多一分危險。不過為了方便大家把網路上或是書上看到的 MapReduce、Hive、Pig 等應用程式拿來執行,所以先請大家啟用遠端連線功能,方便後續操作,以後我們再教大家如何透過 PowerShell 或 CLI 直接操縱 HDInsight Cluster。 要啟用遠端桌面,首先請到 Windows Azure Management Portal,左邊點選虛擬機器,右邊點擊
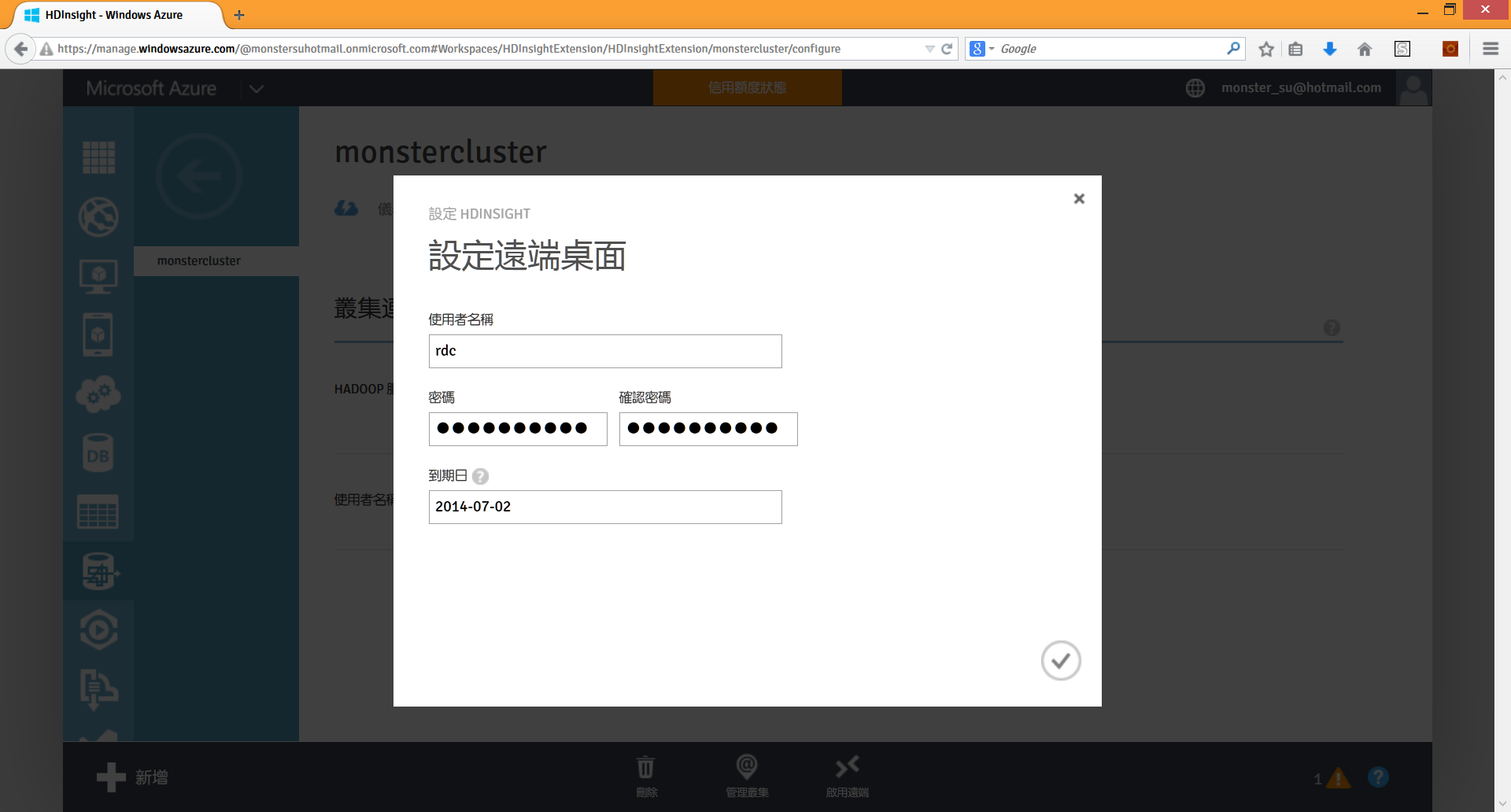
按下啟用遠端圖示之後,HDInsight 會要求我們設定一個不同於之前管理者的新帳號與密碼,到期日最多可以是距今七天的日期:
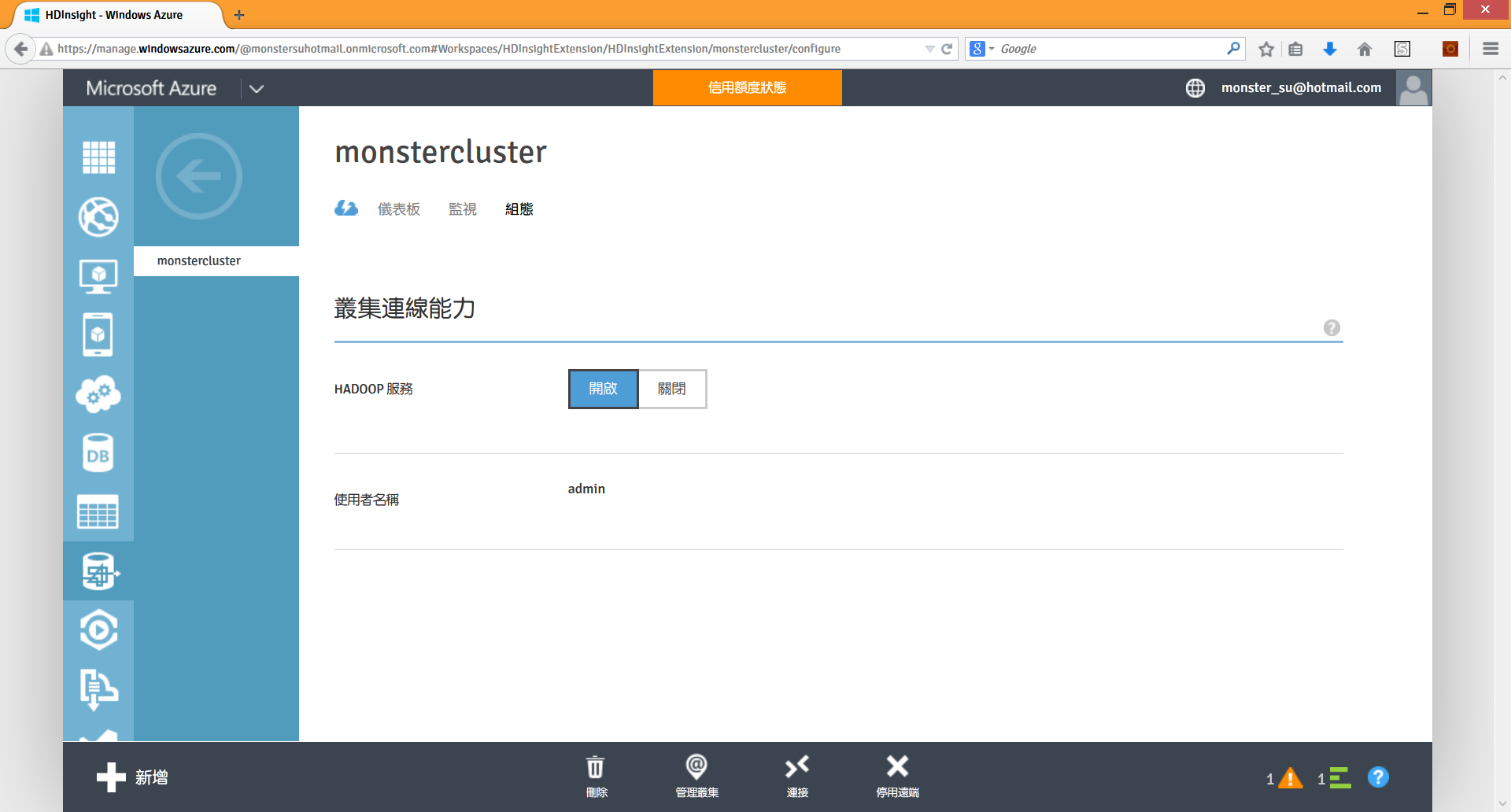
確認之後,HDInsight 就會開始在 Name Node 虛擬機器增加遠端桌面連線所要使用的端點設定:
設定好了之後,剛剛的啟用遠端會變成停用遠端,然後左邊會多出一個連接圖示。按下連接圖示,就會下載遠端桌面連線設定的
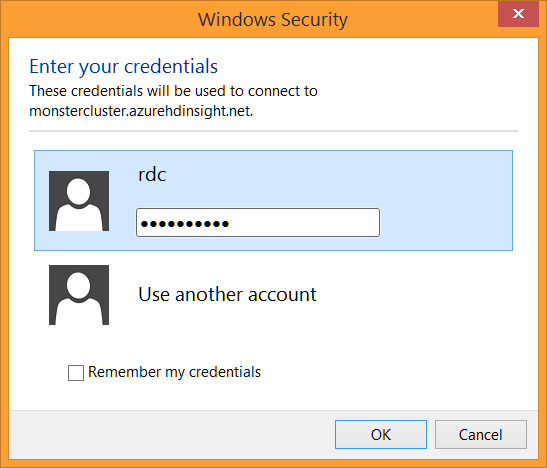
這時請選取遠端桌面連線程式,按下確定按鈕直接執行。遠端桌面連線程式確認帳號密碼之後:
就會與遠端的 HDInsight Cluster 建立連線:
雙擊桌面上的 Hadoop Command Line 捷徑,就會開啟命令列視窗:
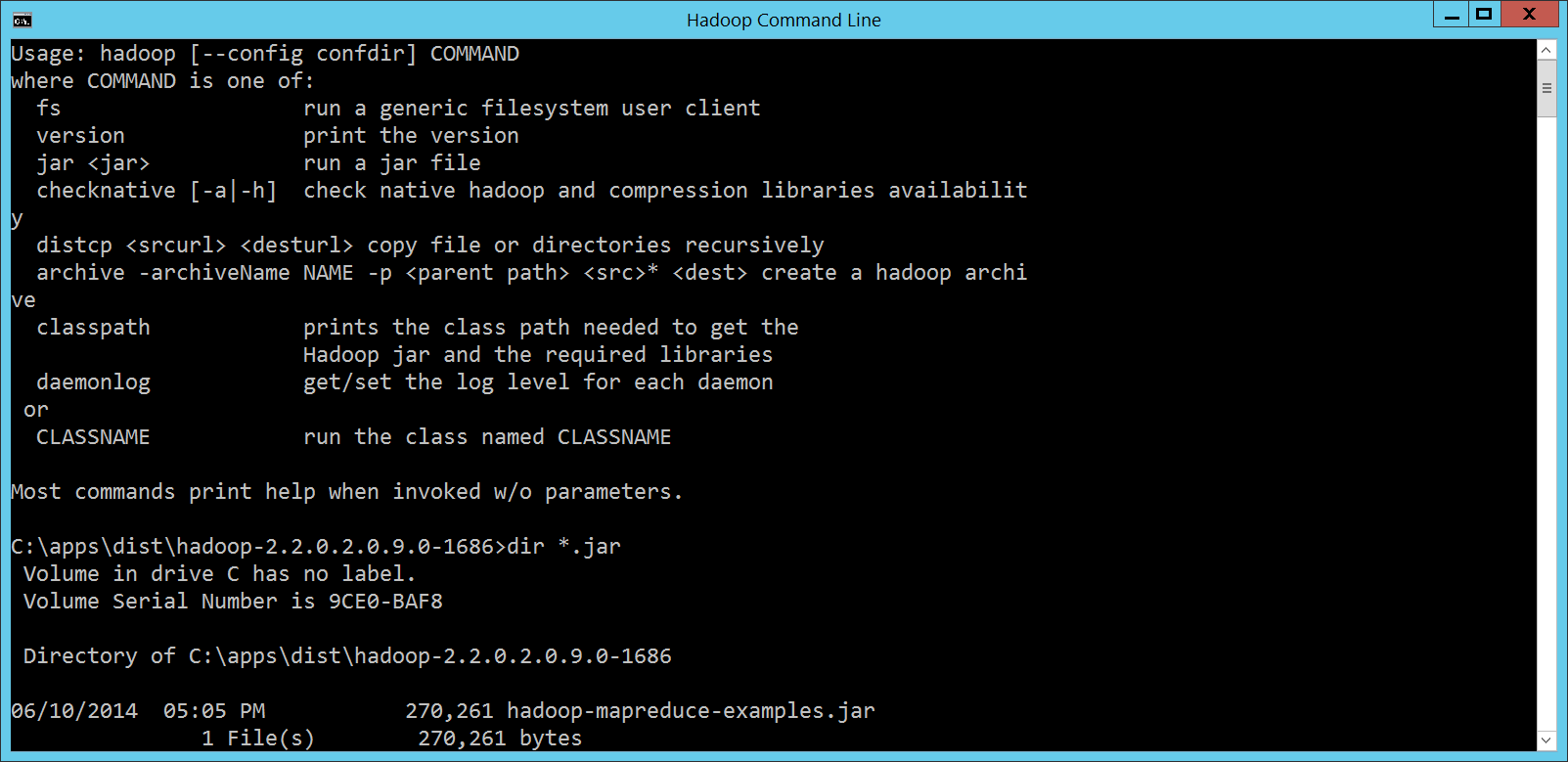
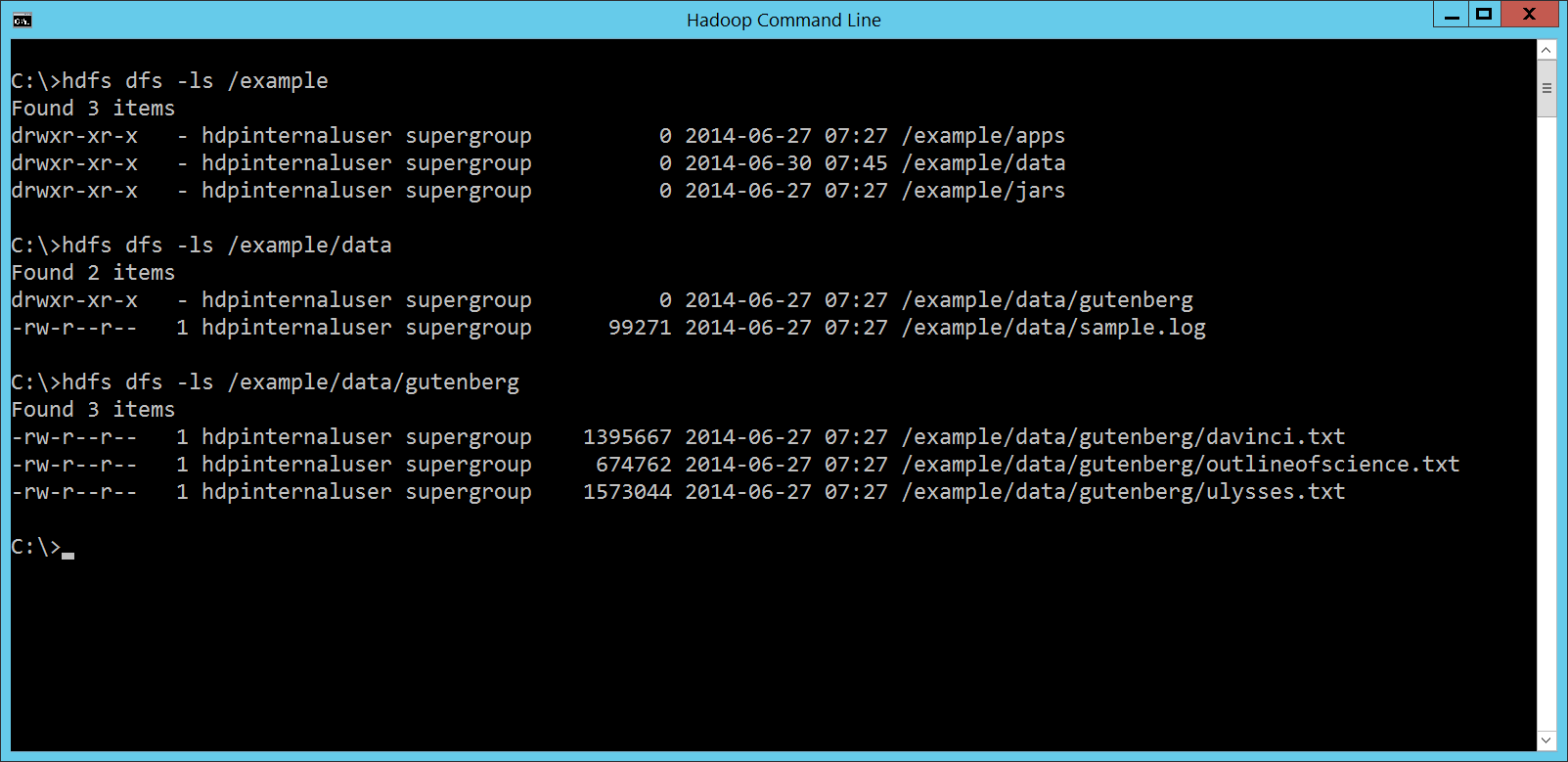
馬上就看到很貼心的 Hello, WordCount!Hadoop 的資料儲存平台是 HDFS,程式運算平台則是 MapReduce。所以要測試 HDInsight Cluster 跟 Hadoop 的相容程度,第一件事當然就是先跑個 MapReduce 程式,處理一下 HDFS 裡面的資料試看看。 每個程式語言剛開始學習的時候,總是要先來個 Hello, World!。MapReduce 的 Hello, World!,國外是 WordCount,也就是統計一下一堆文章裡頭各個單字出現的次數;國內的話有時候我們會用選舉開票做介紹,因為台灣一年到頭都在選舉,選舉開票是大家共有的經驗。 因為 HDInsight Cluster 建置完成之後,會自動把很多 Hadoop 相關的檔案都放到搭配的 Container,裡頭就有 WordCount 範例與測試資料,所以我們還是執行大家最常看到的 WordCount,相關檔案位置如下:
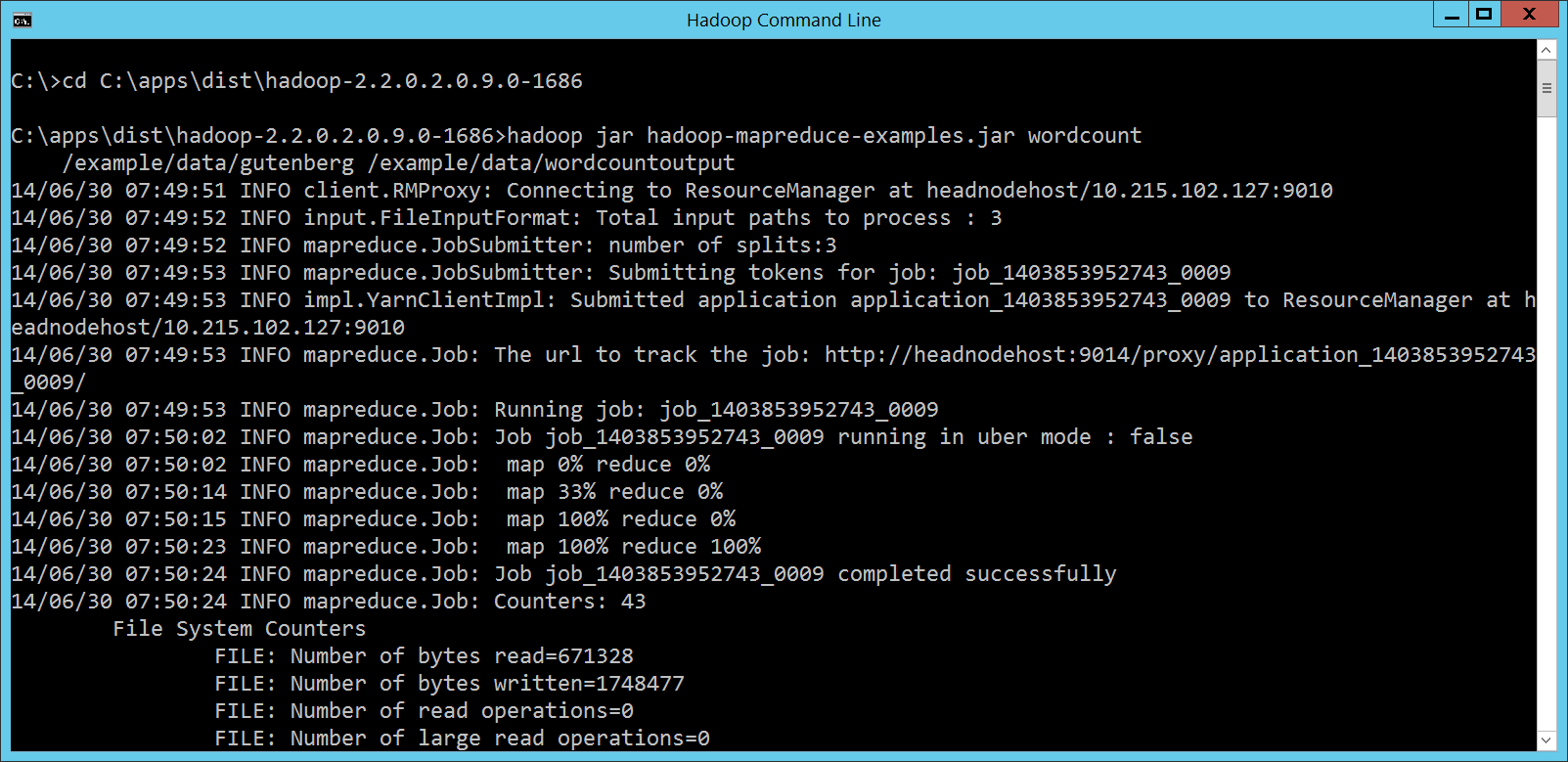
所以這時候,在 Hadoop Command Line 視窗裡頭,就可以輸入底下的指令,執行 WordCount 程式: cd C:\apps\dist\hadoop-2.2.0.2.0.9.0-1686
hadoop jar hadoop-mapreduce-examples.jar wordcount
/example/data/gutenberg /example/data/wordcountoutput
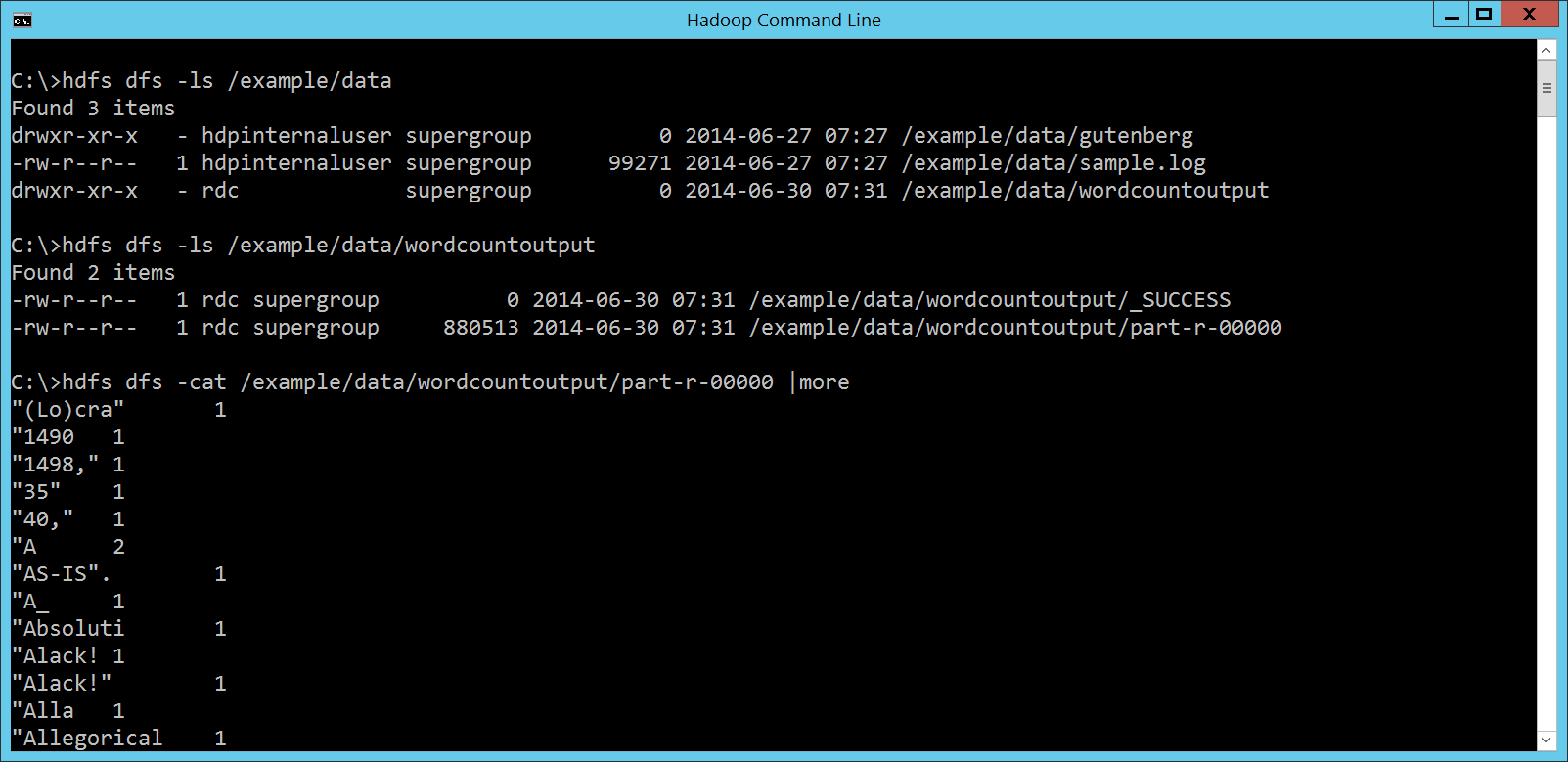
畫面如下:
檢視
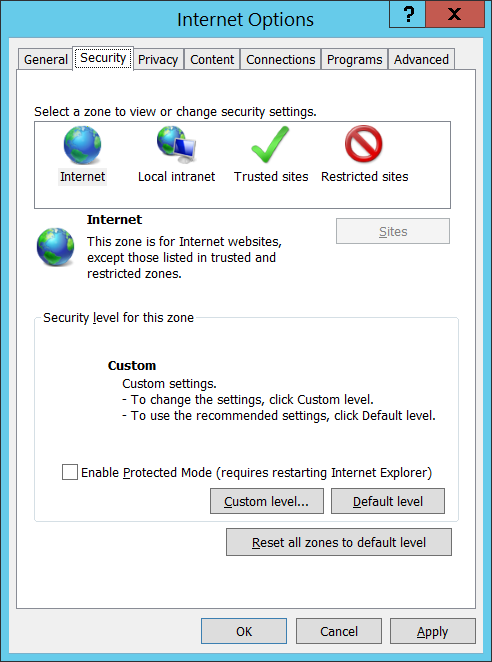
嗯,看起來還蠻順利的! Security Settings因為 HDInsight Cluster 虛擬機器裡的 IE 為了資安的緣故預設不允許下載任何檔案,這會妨礙我們底下範例的進行,所以請打開 IE 的 Internet Options 設定,點選 Security 標籤頁,按下 Custom level… 按鈕:
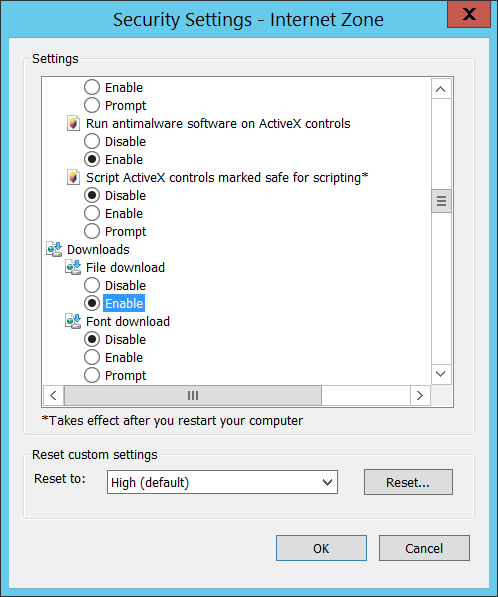
選取 Downloads 底下 File download 的 Enable 選項,這樣才能下載檔案:
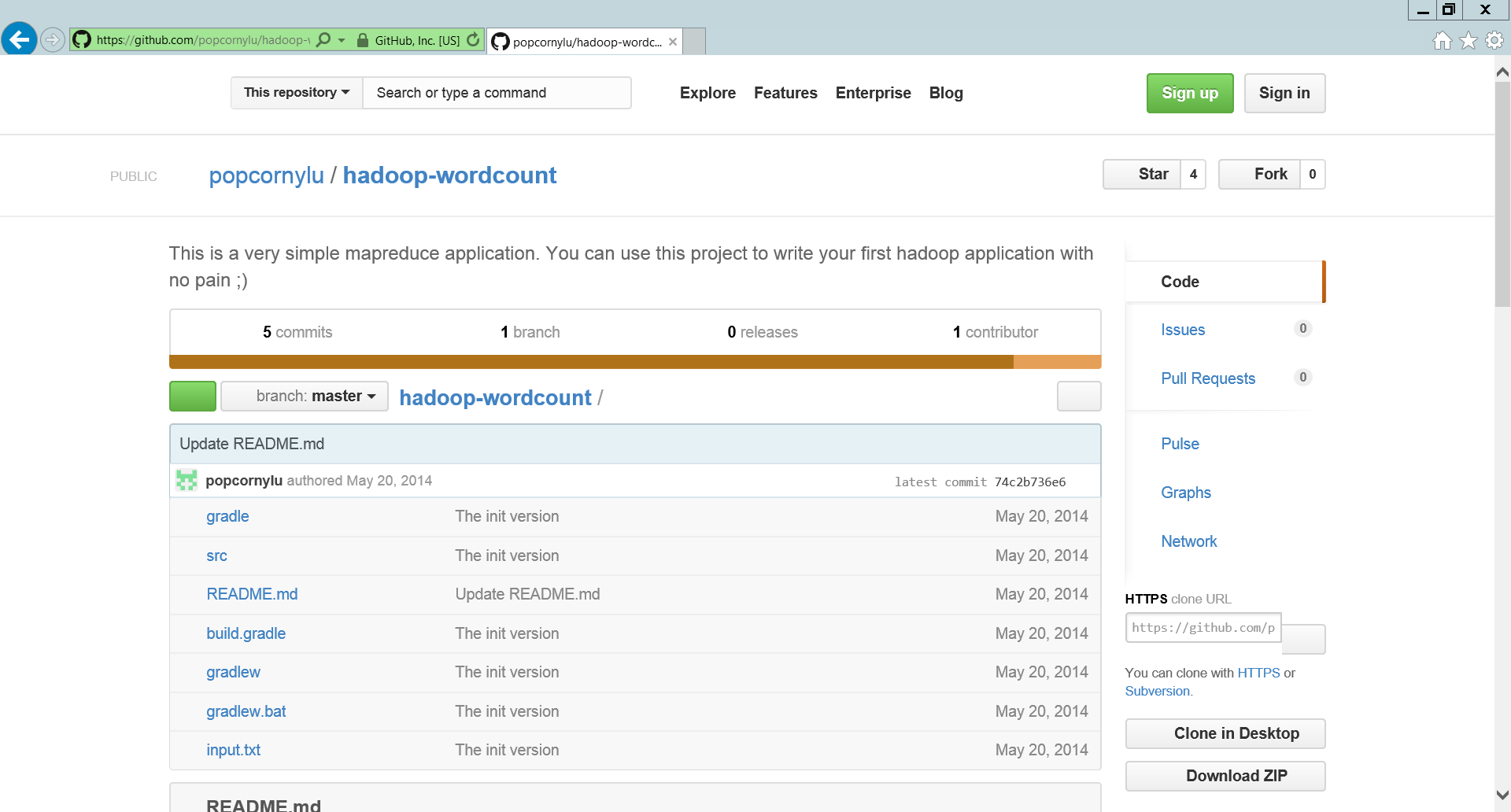
第一次自幹 MapReduce 就上手雖然 WordCount 可以順利執行,但是大家一定會懷疑,說不定那是一個為了讓 HDInsight 可以執行、偷偷經過高度客製化的版本。沒關係,剛好
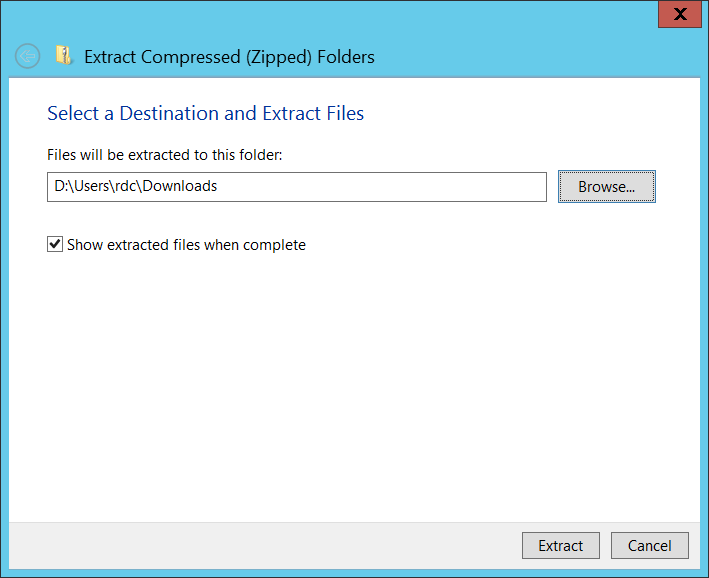
為了簡化執行過程,我們就不透過 Git 操作,直接按下畫面右下角的 Download ZIP 按鈕下載,然後解壓縮到預設的
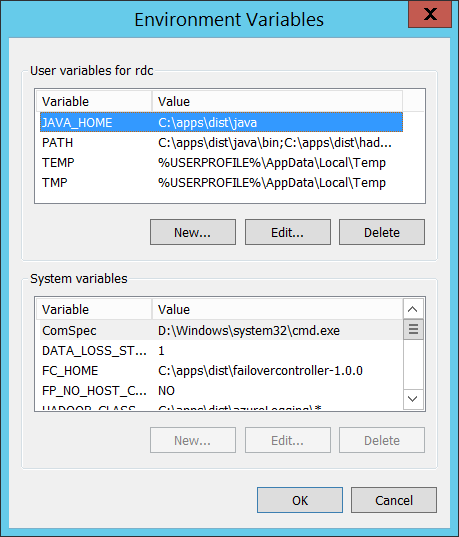
因為要透過 Java SDK 編譯,所以要設定一下
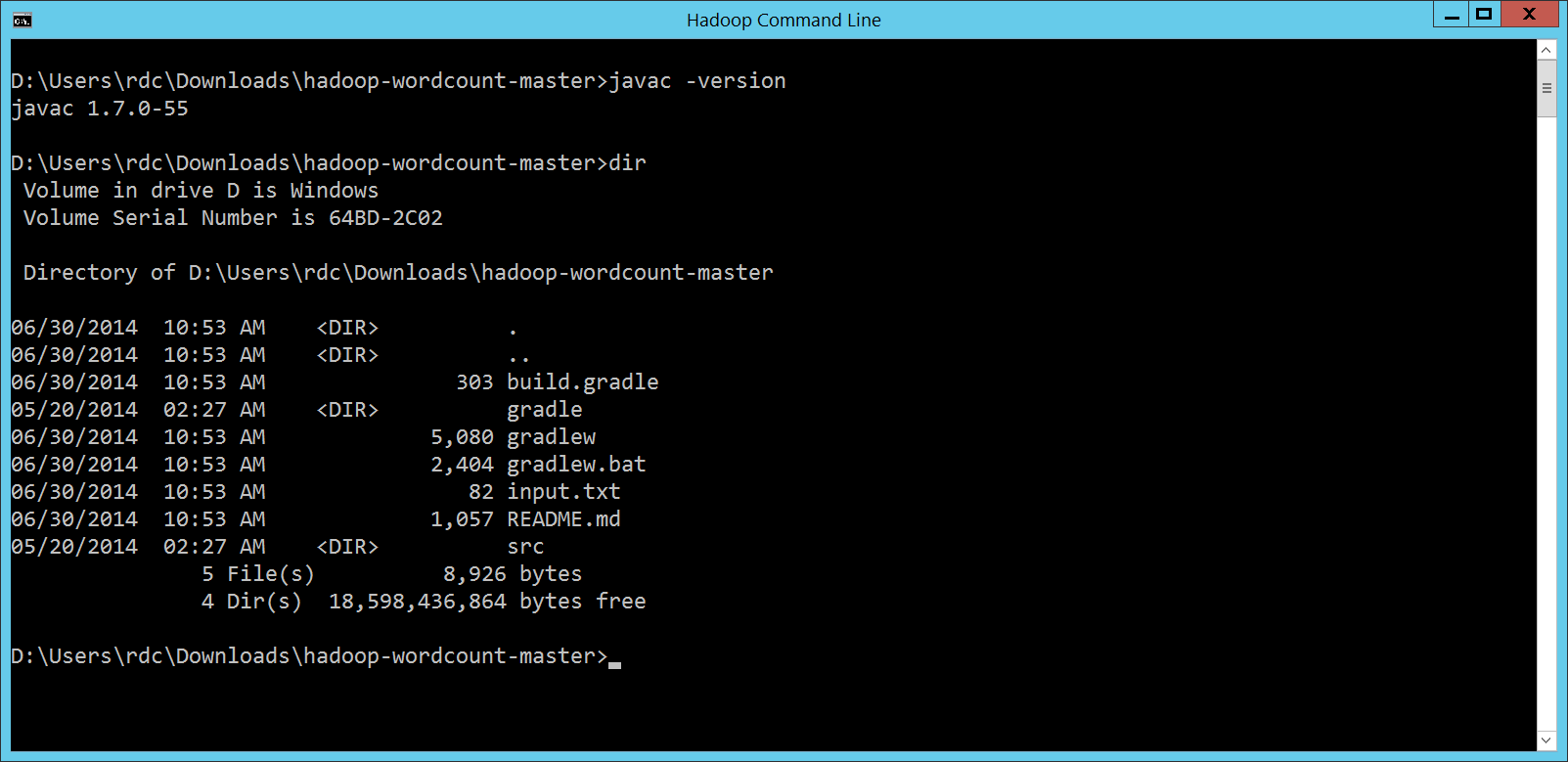
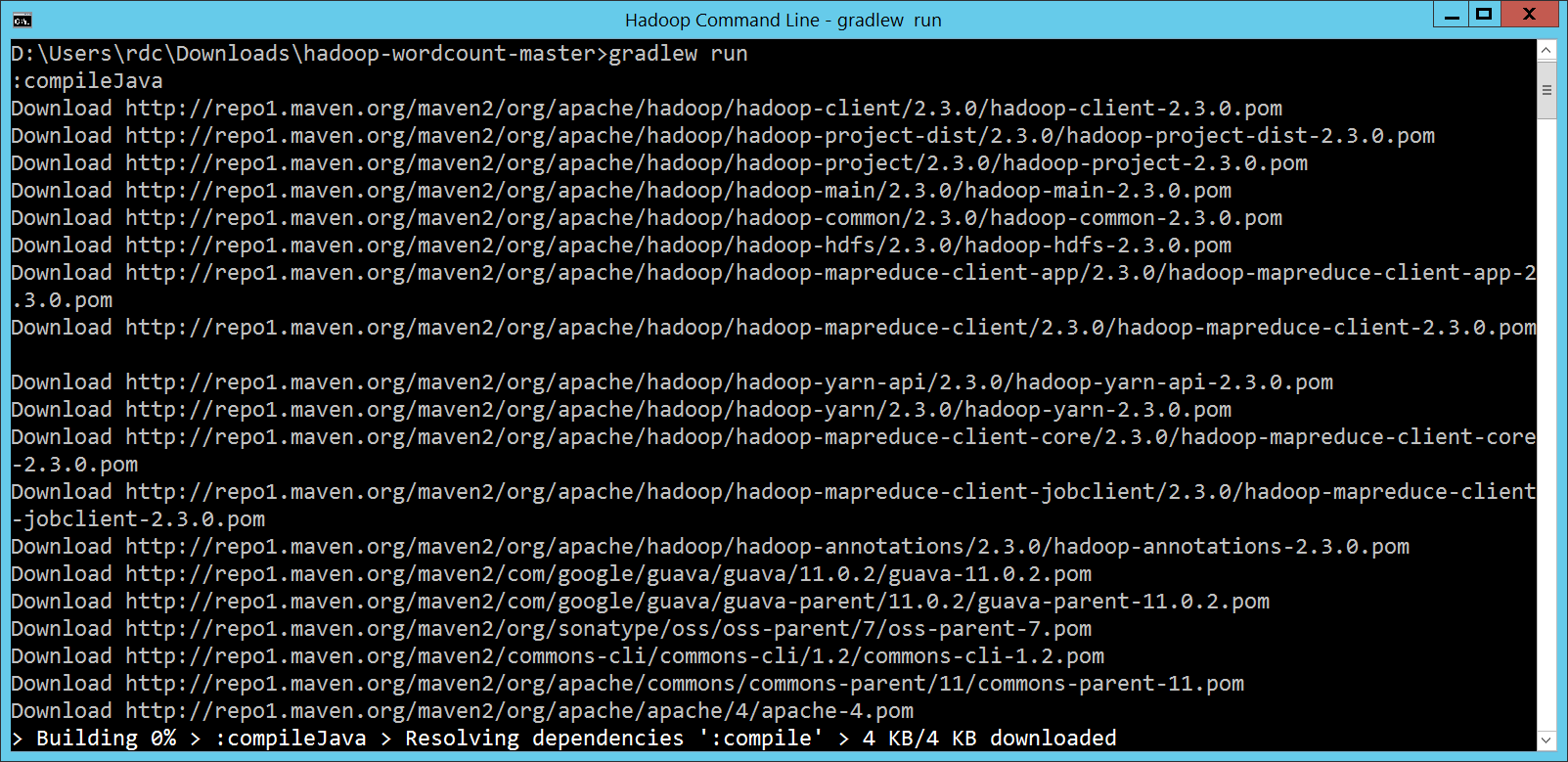
準備好了之後,請重新開啟 Hadoop 視窗,這樣才能抓到剛剛調整過的環境變數。執行一下
確定之後,我們就可以更換到
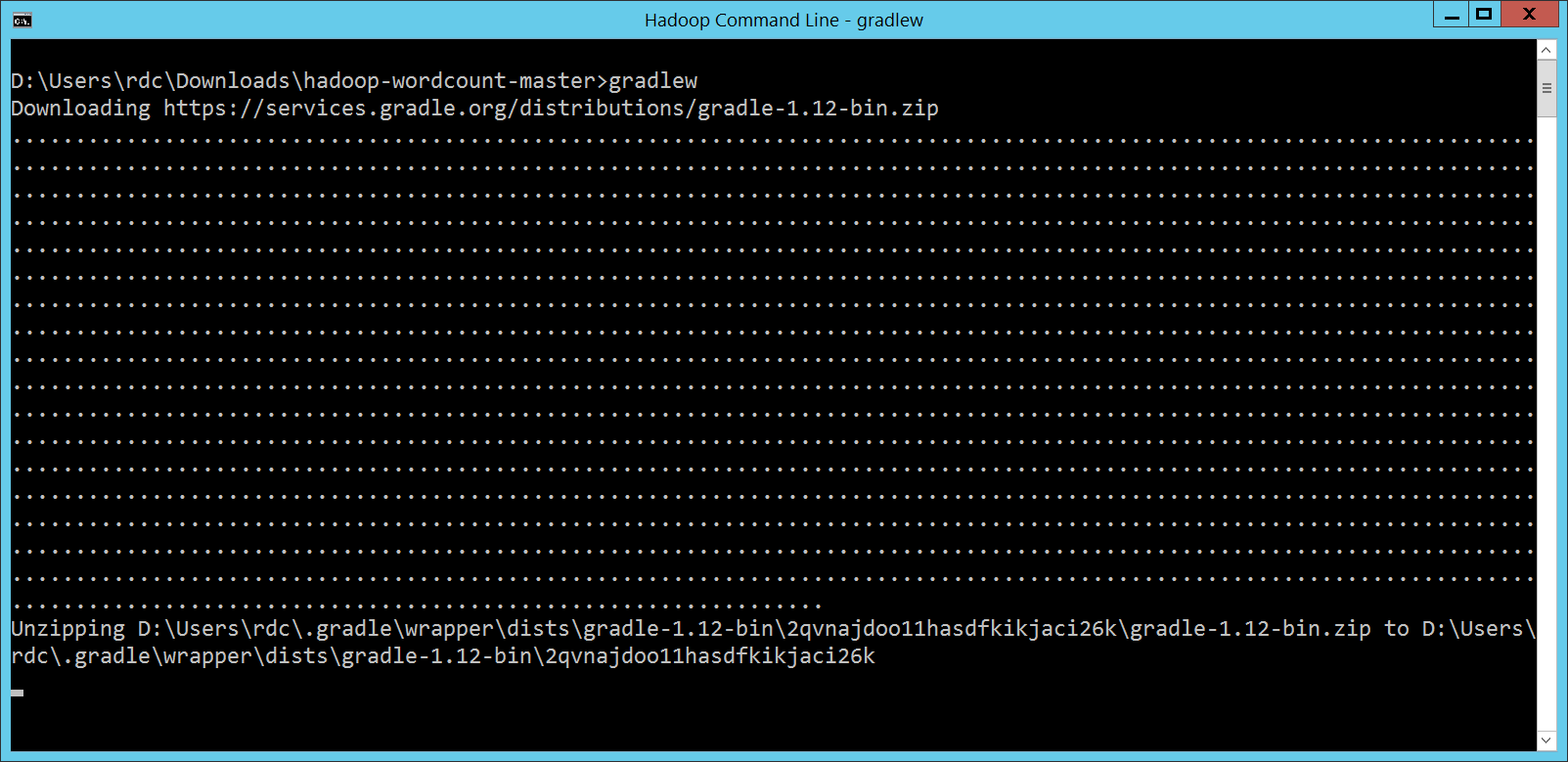
接下來,執行
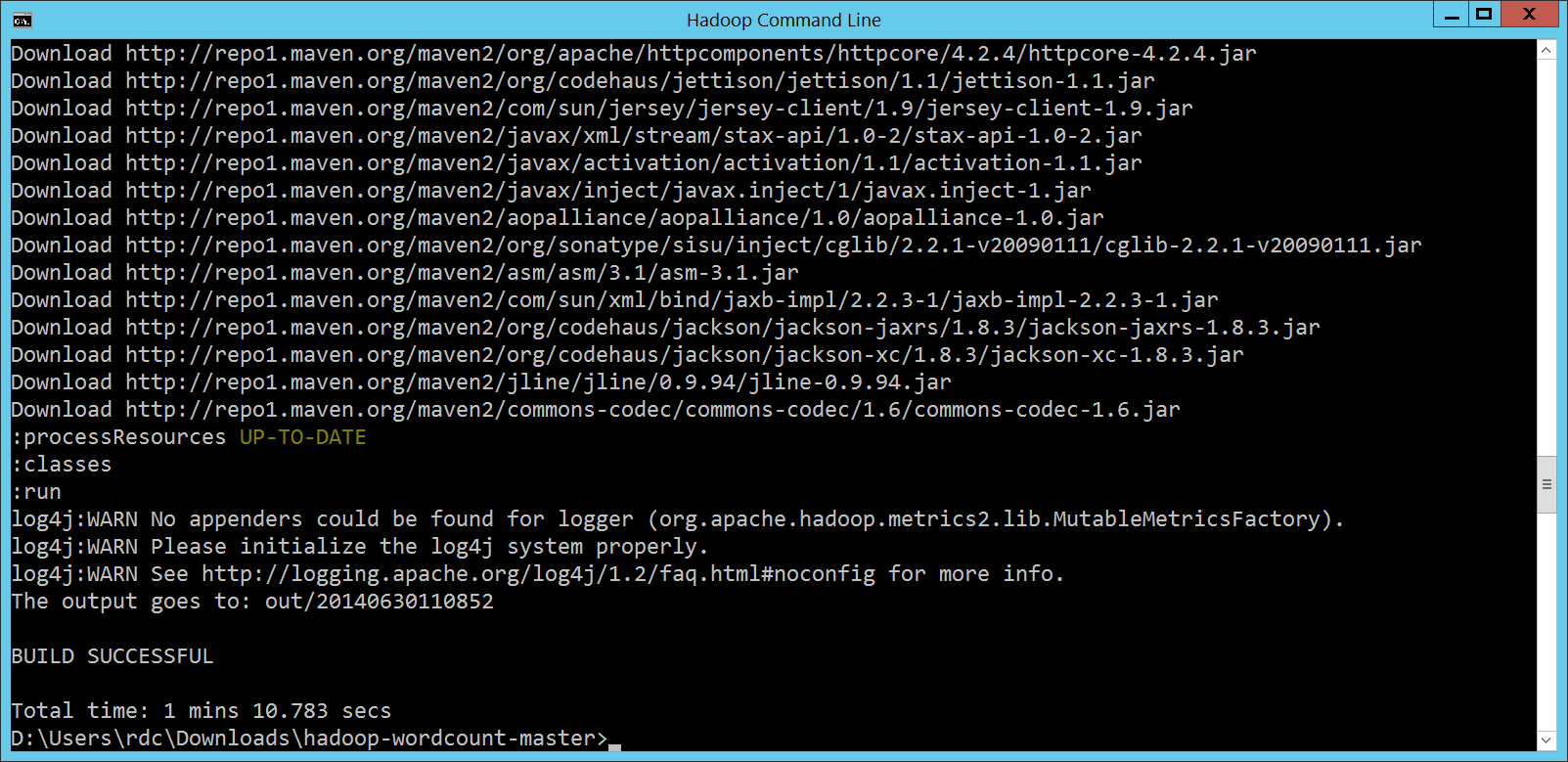
執行結果放在
輸入的
一切都很正常,就像跑在 Linux 裡頭的 Hadoop 一樣! 檢視 package idv.popcorny;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
String in = "input.txt";
String out = "out/" + new SimpleDateFormat("yyyyMMddHHmmss").format(new Date());
if (otherArgs.length >= 1) {
in = otherArgs[0];
}
if (otherArgs.length >= 2) {
out = otherArgs[1];
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCountMapper.class);
job.setCombinerClass(WordCountReducer.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(in));
FileOutputFormat.setOutputPath(job, new Path(out));
System.out.println("The output goes to: " + out);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
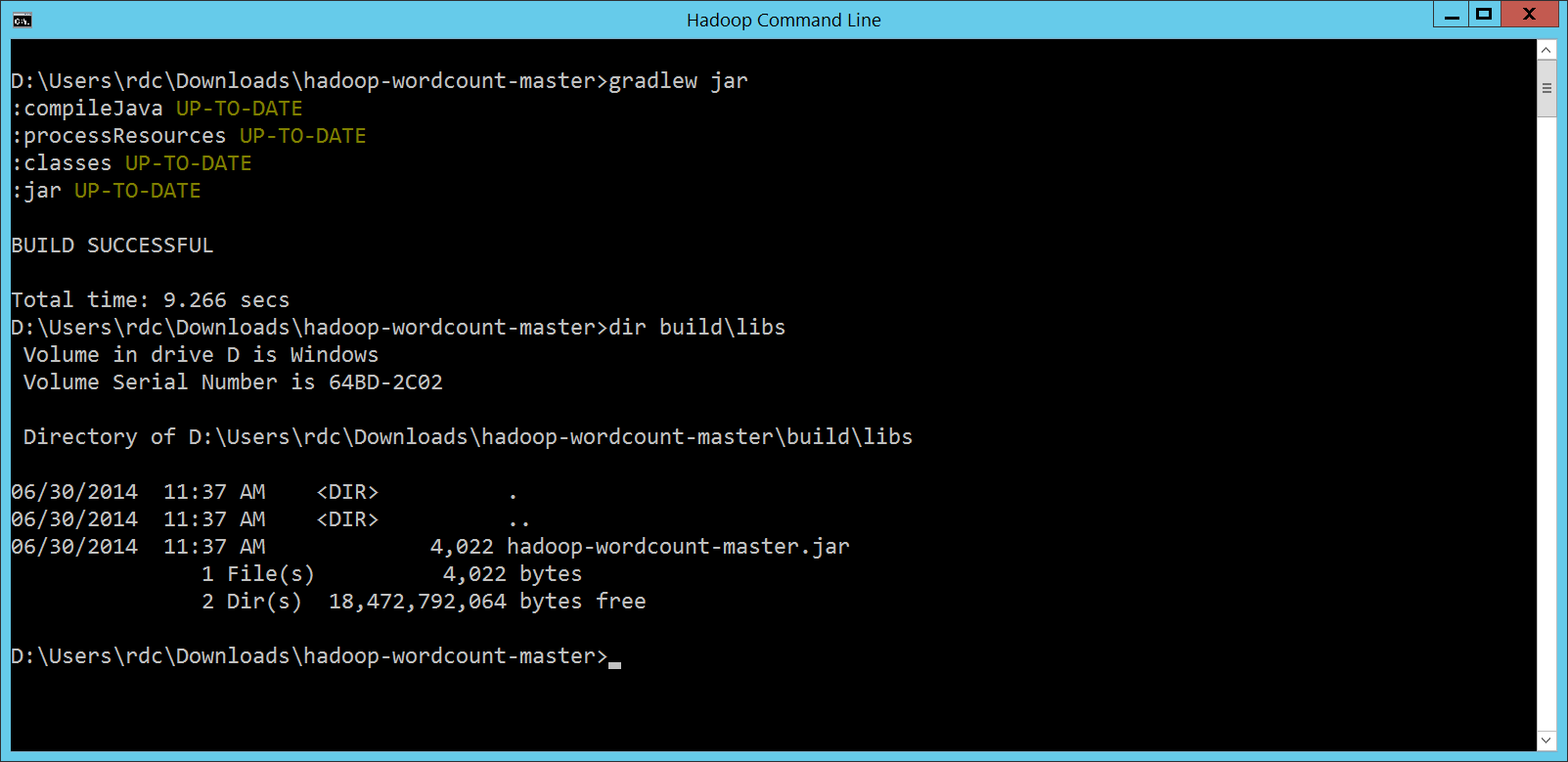
那我們可不可以讓 popcorny 寫的 WordCount 程式,處理 HDInsight 內建的測試資料呢?當然可以!我們可以透過
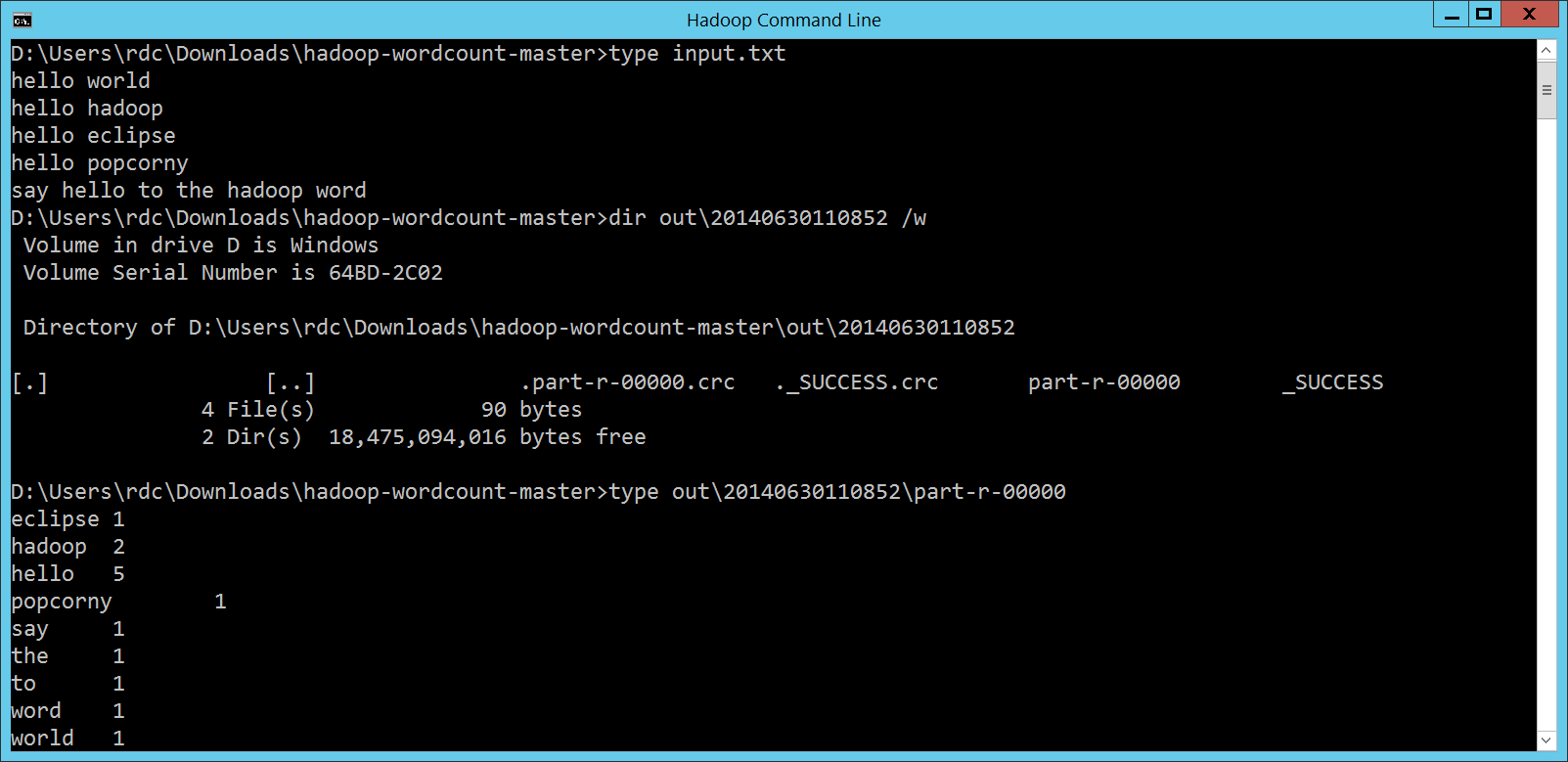
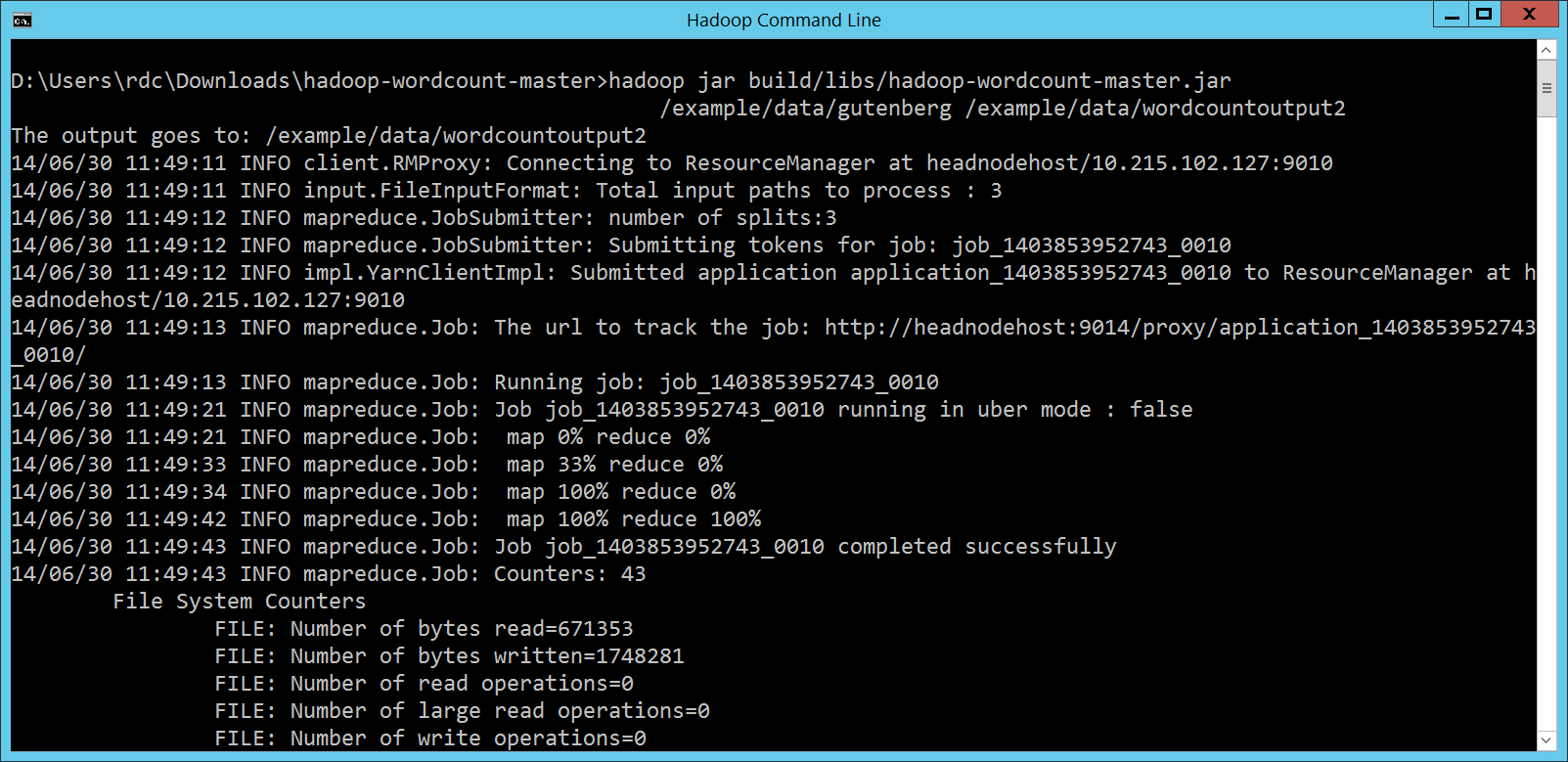
然後我們就可以仿照之前執行 HDInsight 提供的 WordCount 程式,執行我們的 hadoop jar build/libs/hadoop-wordcount-master.jar
/example/data/gutenberg /example/data/wordcountoutput2
畫面如下:
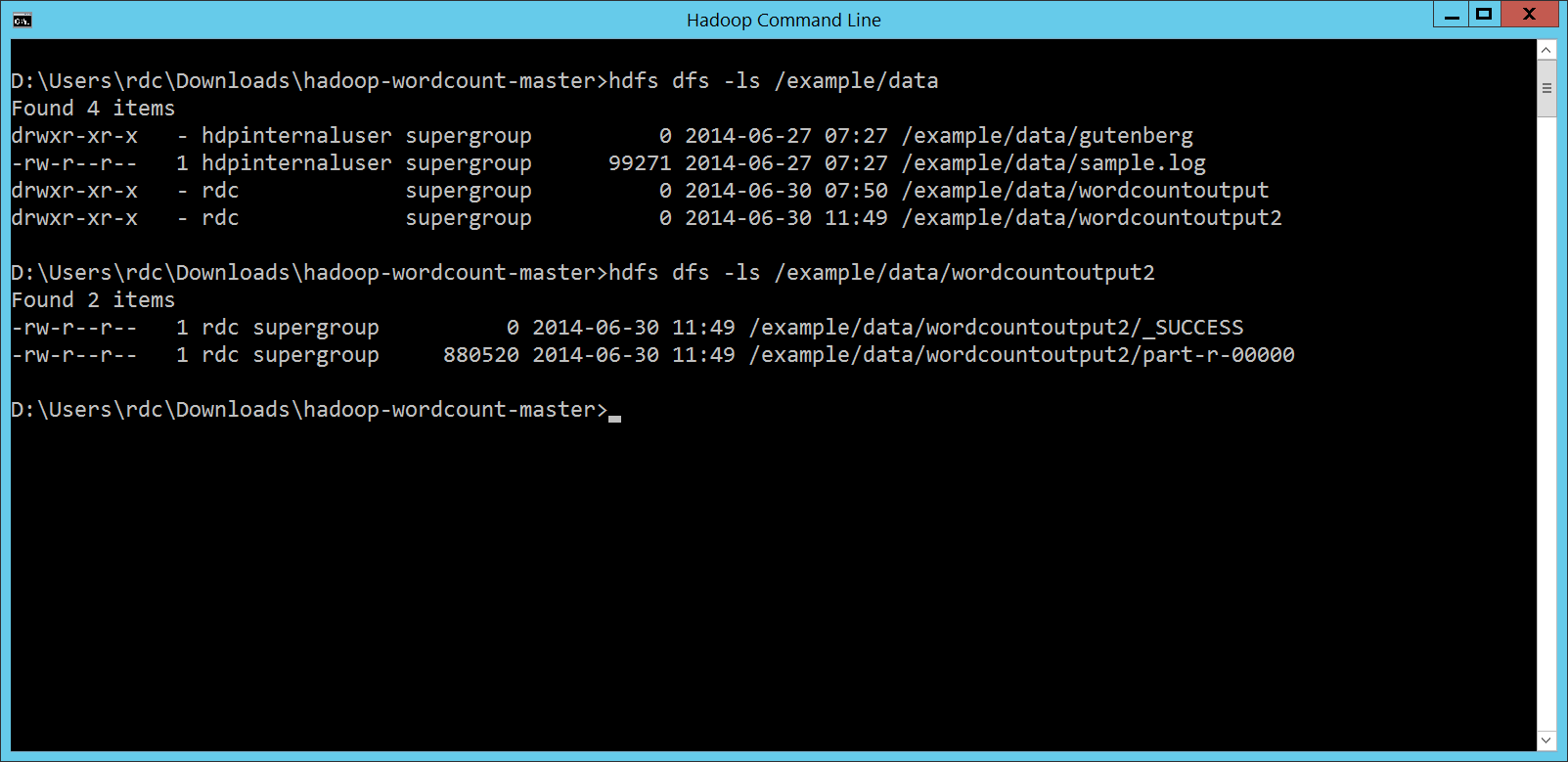
結果也順利產生:
結論透過 Gradle 編譯 Java 程式的方便性,可以大幅度簡化編譯 MapReduce 程式的複雜度。透過 HDInsight 執行 MapReduce 程式的方便性,又可以大幅度降低佈建 Hadoop 環境的複雜度,而且並沒有因為這些方便性破壞了相容性喔! 很棒吧! PS. 記得把 HDInsight Cluster 殺掉喔! |

相關文章
關於作者

目前從事教育訓練工作。自認為會的技術不多,但是學不會的也不多,最擅長把老闆交代的工作,以及找不到老師教的技術,想辦法變成自己的專長。