 Java 學習之路
Java 學習之路
Hadoop as a Service(3)Gradle vs. HDInsight x Hadoop
|
在第二篇文章「Hadoop as a Service(2)在 HDInsight Cluster 執行 MapReduce 程式」裡頭,我們一共執行了三次的 MapReduce 程式:
其實,不知道大家有沒有注意到,第 2 次跟第 3 次這兩次,雖然都是執行同一個程式,但是執行的方式不太一樣?
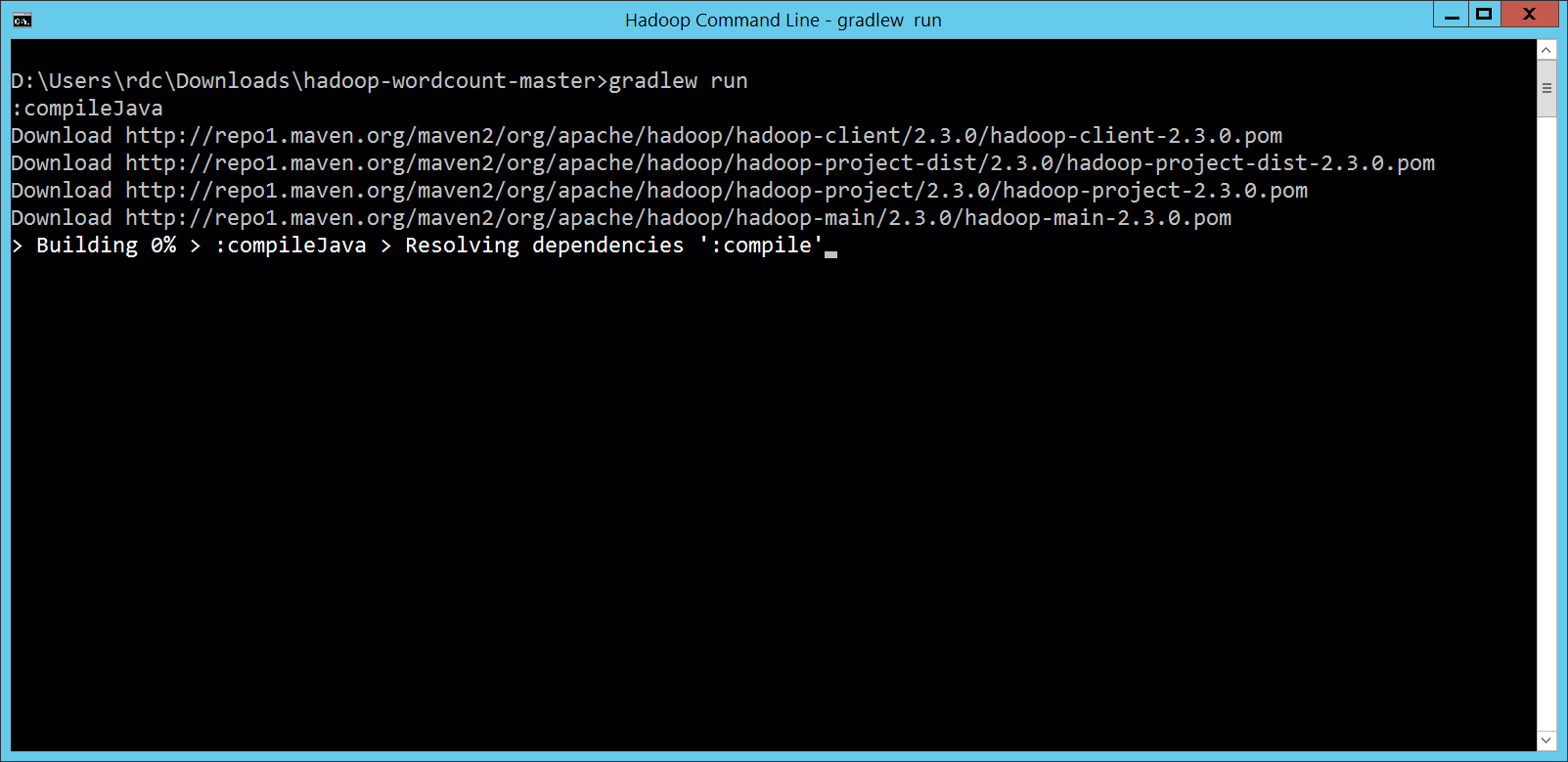
第 2 次的時候,我們透過 注意到這個差異了嗎? MapReduce 程式第 1 次的執行方式一般來說,MapReduce 程式寫好之後,我們總是會先包裝成一個 JAR 檔案,再 Submit 到 Hadoop Cluster,透過 hadoop jar hadoop-mapreduce-examples.jar wordcount
/example/data/gutenberg /example/data/wordcountoutput
<property>
<name>mapreduce.application.classpath</name>
<value>
%HADOOP_CONF_DIR%,
%HADOOP_COMMON_HOME%/share/hadoop/common/*,
%HADOOP_COMMON_HOME%/share/hadoop/common/lib/*,
%HADOOP_HDFS_HOME%/share/hadoop/hdfs/*,
%HADOOP_HDFS_HOME%/share/hadoop/hdfs/lib/*,
%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/*,
%HADOOP_MAPRED_HOME%/share/hadoop/mapreduce/lib/*,
%HADOOP_YARN_HOME%/share/hadoop/yarn/*,
%HADOOP_YARN_HOME%/share/hadoop/yarn/lib/*
</value>
<description>
CLASSPATH for MR applications. A comma-separated list of CLASSPATH entries
</description>
</property>
二方面應該也會處理一些權限的問題,比方說透過 如果還要再找一些理由的話,那就是我們用來撰寫 MapReduce 程式與執行 MapReduce 程式所使用的機器,通常不會是同一台,所以為了 Submit 上傳檔案方便,包成 JAR 檔案也是一個比較好的作法。 MapReduce 程式第 2 次的執行方式第 2 次執行 MapReduce 程式的時候,我們是透過 Gradle 裡頭 gradlew run 這裡面其實有一個小問題,但是也間接證明了兩件事。 小問題是,我們並沒有提供執行 Hadoop 程式所需的相關 JAR 檔案,對吧?再往前推,如果我們沒有提供相關 JAR 檔案,那應該連編譯都會出問題吧? 沒錯,我們有提供相關 JAR 檔案: dependencies {
compile 'org.apache.hadoop:hadoop-client:2.3.0'
}
根據 Gradle 的說明,因為
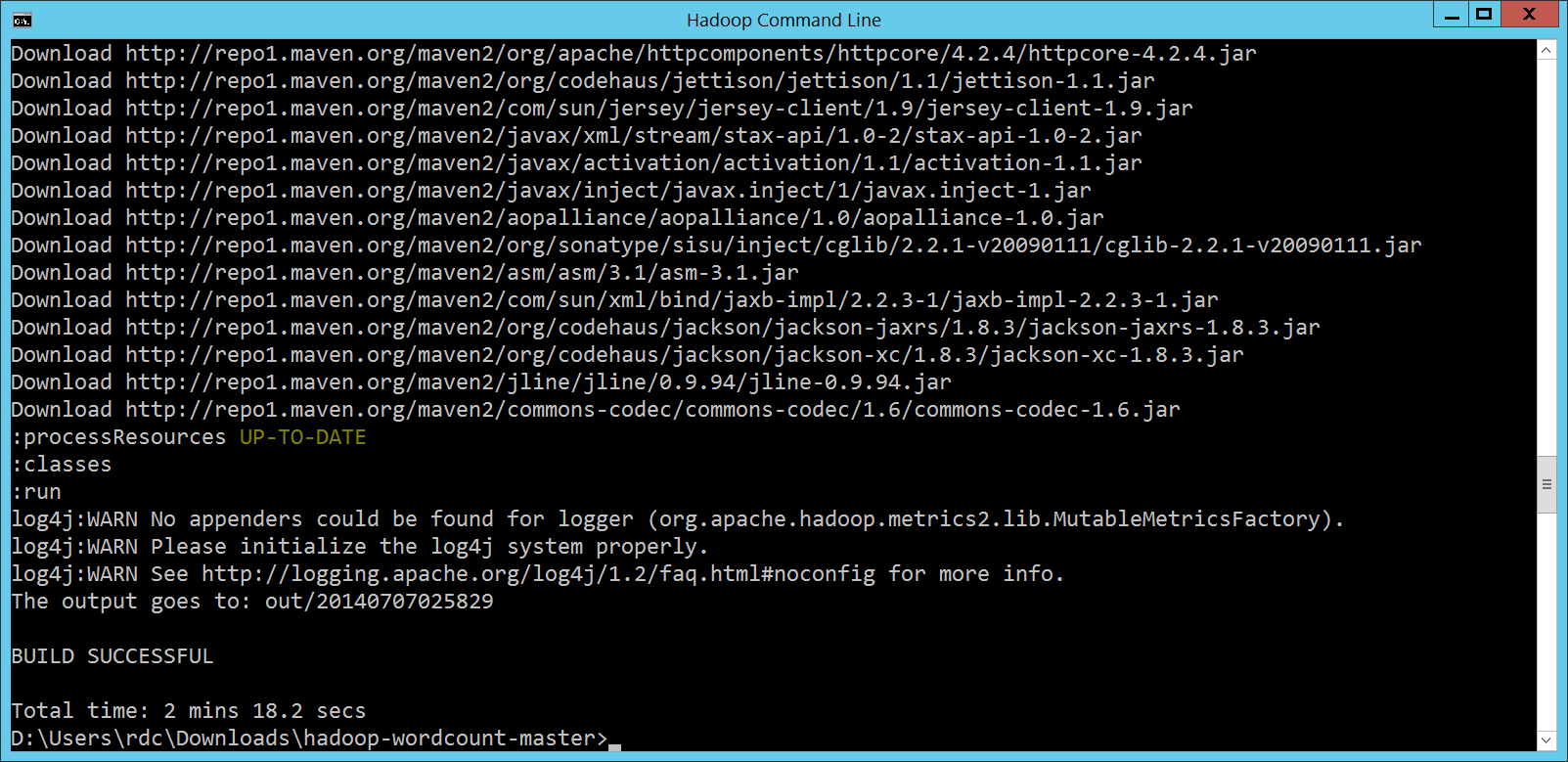
小問題知道了,那間接證明的兩件事,又是什麼呢? 建立 HDInsight Cluster 的時候,我選定的 Hadoop 版本是 2.2.0,但是 popcorny 在 第二件事其實是第一件事衍伸出來的,我們的 Client 端,使用的是 Apache 提供的原始 Hadoop 相關 JAR 檔案,但是我們的 Server 環境,使用的是 Hortonworks 移植到 Windows 平台、再經由 Microsoft 整合了http://www.codedata.com.tw/wp-content/uploads/2014/07/ Azure Blob Storage 的重重修改版本,能夠順利執行,其實也證明了 HDInsight 跟 Hadoop 之間的相容性看起來很不錯呦!
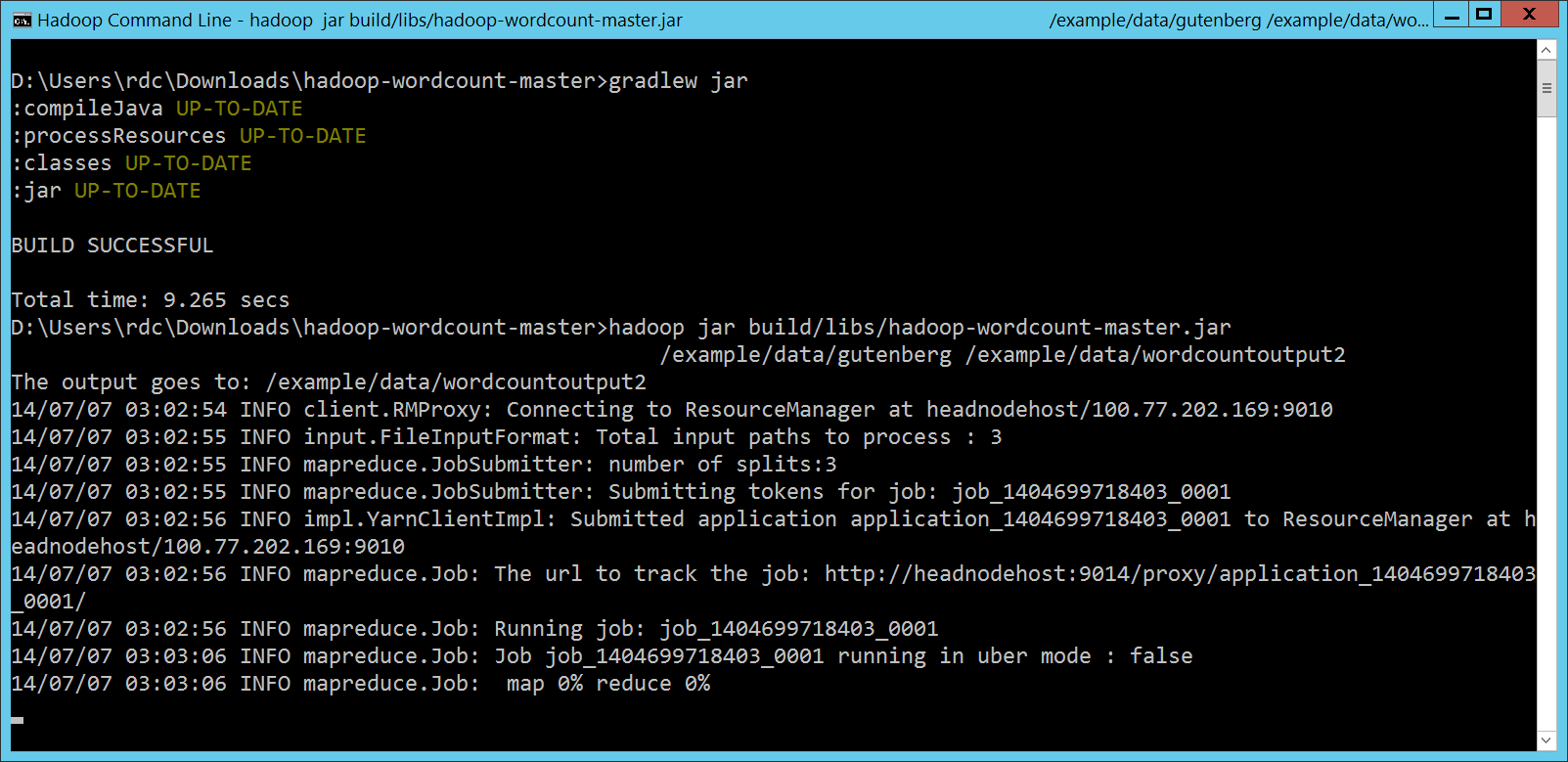
MapReduce 程式第 3 次的執行方式第 3 次執行 MapReduce 程式的時候,我們是透過 Gradle 裡頭 gradlew jar
hadoop jar build/libs/hadoop-wordcount-master.jar
/example/data/gutenberg /example/data/wordcountoutput2
其實,故事的一開始不是這樣的。 當時面臨兩個問題:一是如何表示 HDInsight Cluster 上的資料位置,二是如何把這些位置當作參數傳遞給 Gradle? 先解決第二個問題,也就是如何把這些位置當作參數傳遞給 Gradle。 因為我也只是個 Gradle 的門外漢,所以只好上網路上找了一下資料,發現最簡單的方式,就是用 run {
if (project.hasProperty('args')) {
args project.args.split('\\s+')
}
}
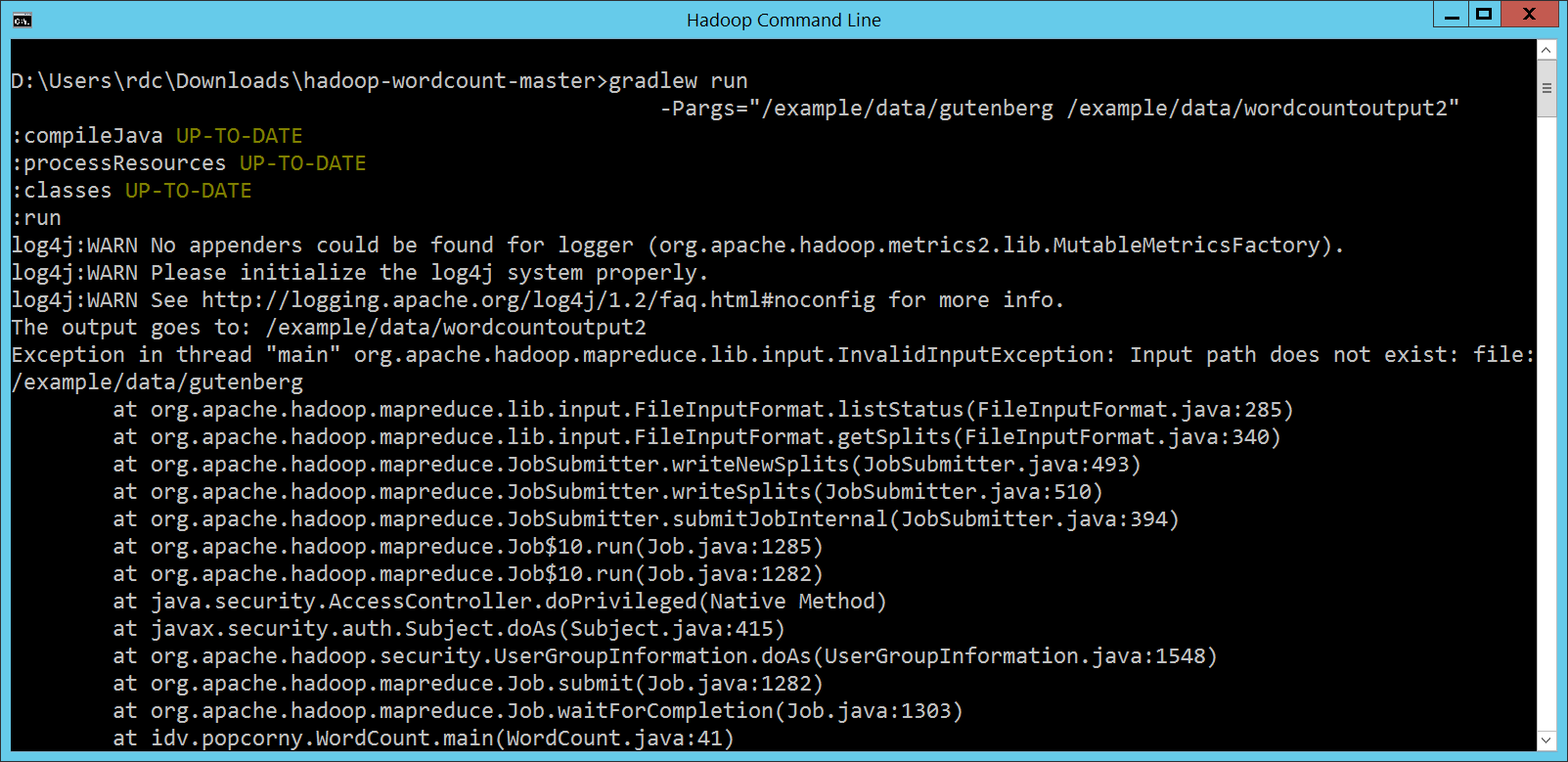
Gradle 指令就模仿第 1 次執行 MapReduce 程式的寫法,改成: gradlew run -Pargs="/example/data/gutenberg /example/data/wordcountoutput2" 看到 不過 Hadoop 似乎把這樣的路徑寫法當成 Local Native File System,
因為我們的 Server 端環境,是架在 Azure 上的 HDInsight Cluster,底層是 Azure Blob Storage 封裝而成的 HDFS。如果要存取架在 Azure Blob Storage 上的這個 HDFS 檔案系統裡面的資料,比方說
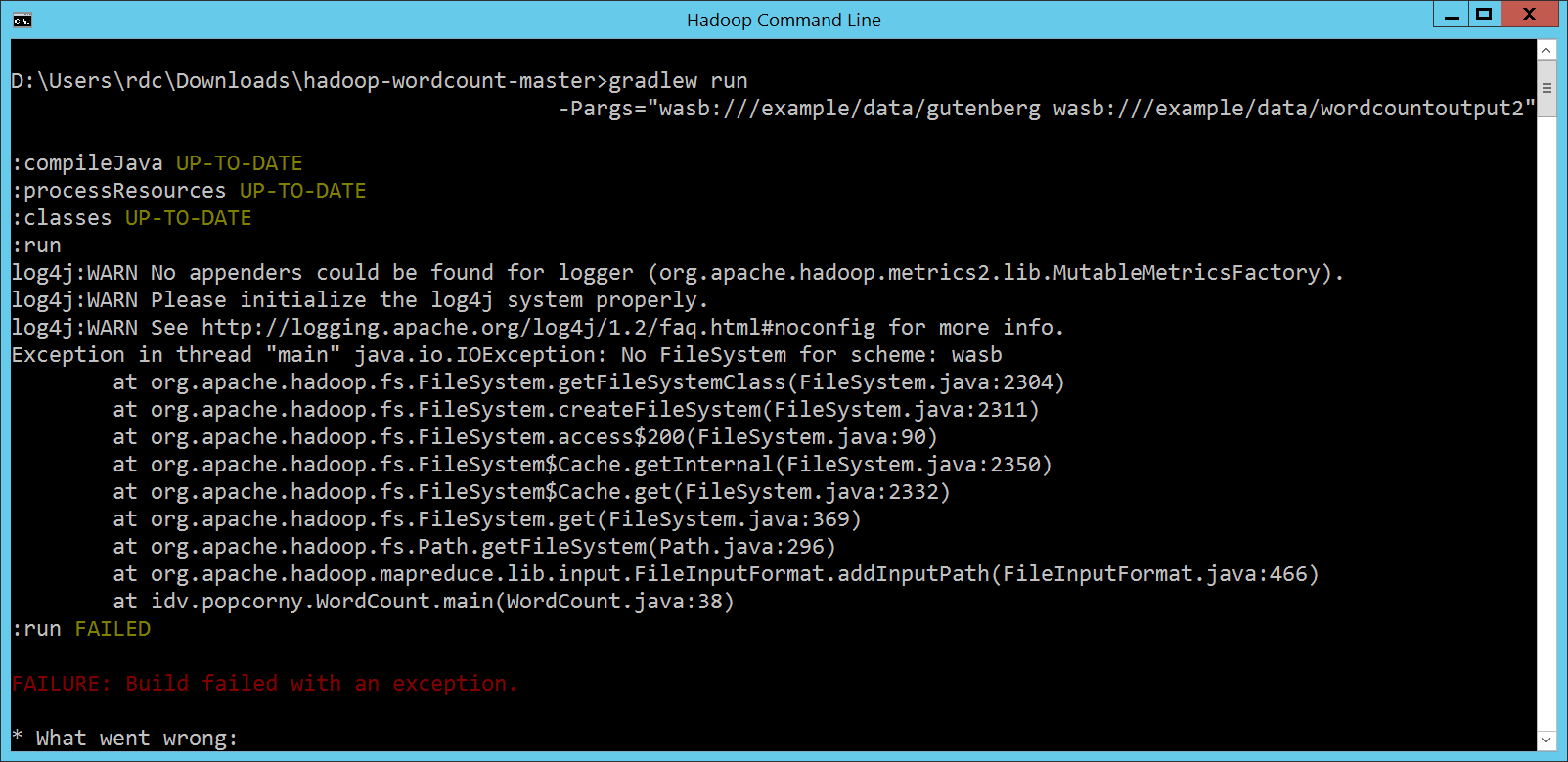
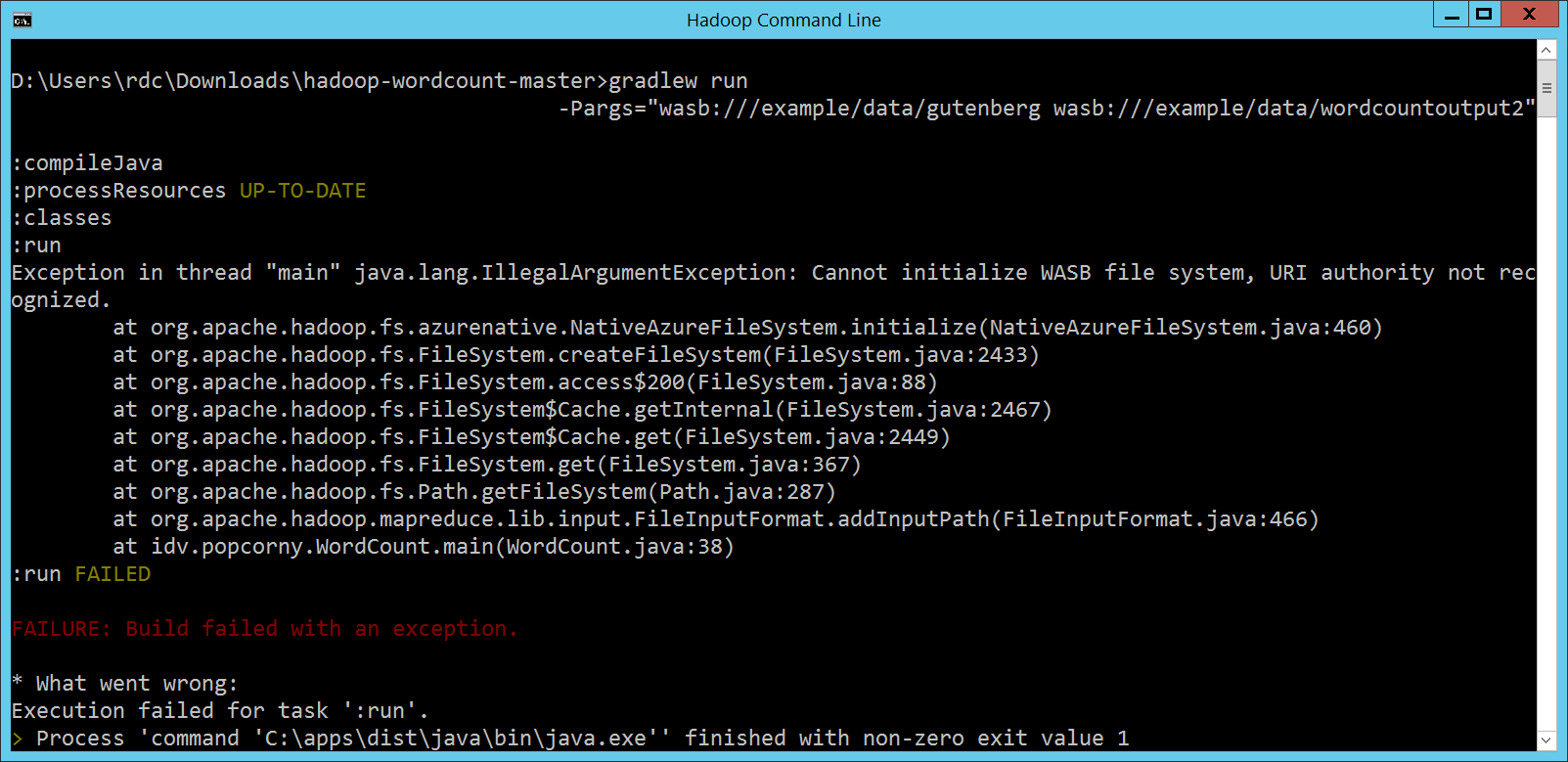
所以剛剛第一個問題,如何表示 HDInsight Cluster 上的資料位置,答案就很簡單,事實上我們在第 1 次執行 MapReduce 程式的時候就碰過這個問題了。沒關係,看不懂 gradlew run -Pargs="wasb:///example/data/gutenberg wasb:///example/data/wordcountoutput2"
還是不行,那再試一下第三種寫法: gradlew run -Pargs="wasb://[email protected]/example/data/gutenberg wasb://[email protected]/example/data/wordcountoutput2" 仍然不行,因為看不懂
等等,在 HDInsight Cluster 裡頭看不懂 冷靜下來,從「MapReduce 程式第 2 次的執行方式」那一段,我們不是很開心地用 Apache Hadoop Client 在 HDInsight Cluster 裡頭執行嗎?那是不是說,我們的 MapReduce 程式不知道什麼是 既然有了這樣的想法,那就來驗證一下。參考 HDInsight Cluster 剛剛的 /*
dependencies {
compile 'org.apache.hadoop:hadoop-client:2.3.0'
}
*/
project.ext.HADOOP_HOME = "$System.env.HADOOP_HOME".replaceAll('\\\\', '/')
project.ext.HADOOP_CLASSPATH = "C:/apps/dist/azureLogging"
dependencies {
compile fileTree(dir: HADOOP_CLASSPATH, include: '*.jar')
compile fileTree(dir: HADOOP_HOME, include: '*.jar')
compile fileTree(dir: HADOOP_HOME + '/share/hadoop/common', include: '*.jar')
compile fileTree(dir: HADOOP_HOME + '/share/hadoop/common/lib', include: '*.jar')
compile fileTree(dir: HADOOP_HOME + '/share/hadoop/hdfs', include: '*.jar')
compile fileTree(dir: HADOOP_HOME + '/share/hadoop/hdfs/lib', include: '*.jar')
compile fileTree(dir: HADOOP_HOME + '/share/hadoop/mapreduce', include: '*.jar')
compile fileTree(dir: HADOOP_HOME + '/share/hadoop/mapreduce/lib', include: '*.jar')
compile fileTree(dir: HADOOP_HOME + '/share/hadoop/tools', include: '*.jar')
compile fileTree(dir: HADOOP_HOME + '/share/hadoop/tools/lib', include: '*.jar')
compile fileTree(dir: HADOOP_HOME + '/share/hadoop/yarn', include: '*.jar')
compile fileTree(dir: HADOOP_HOME + '/share/hadoop/yarn/lib', include: '*.jar')
}
然後不要急著執行 Gradle,先到目前 HDInsight Cluster 的使用者 Home Directory 底下,以我們的範例就是
要殺就殺的徹底一點,
再從頭執行一次 Gradle: gradlew
這時會下載 Gradle 相關程式。然後再執行: gradlew run -Pargs="wasb:///example/data/gutenberg wasb:///example/data/wordcountoutput2" 這時候如果仔細觀察,會發現 Gradle 並沒有像之前一樣去下載 Apache Hadoop Client 相關 JAR 檔案,那就表示我們的 Dependency 設定生效了。
但是再往下看,雖然這次因為使用 HDInsight 本身的 JAR 檔案,所以終於看懂了 Exception in thread "main" java.lang.IllegalArgumentException: Cannot initialize WASB file system, URI authority not recognized.
at org.apache.hadoop.fs.azurenative.NativeAzureFileSystem.initialize(NativeAzureFileSystem.java:460)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2433)
at org.apache.hadoop.fs.FileSystem.access$200(FileSystem.java:88)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:2467)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:2449)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:367)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:287)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.addInputPath(FileInputFormat.java:466)
at idv.popcorny.WordCount.main(WordCount.java:38)
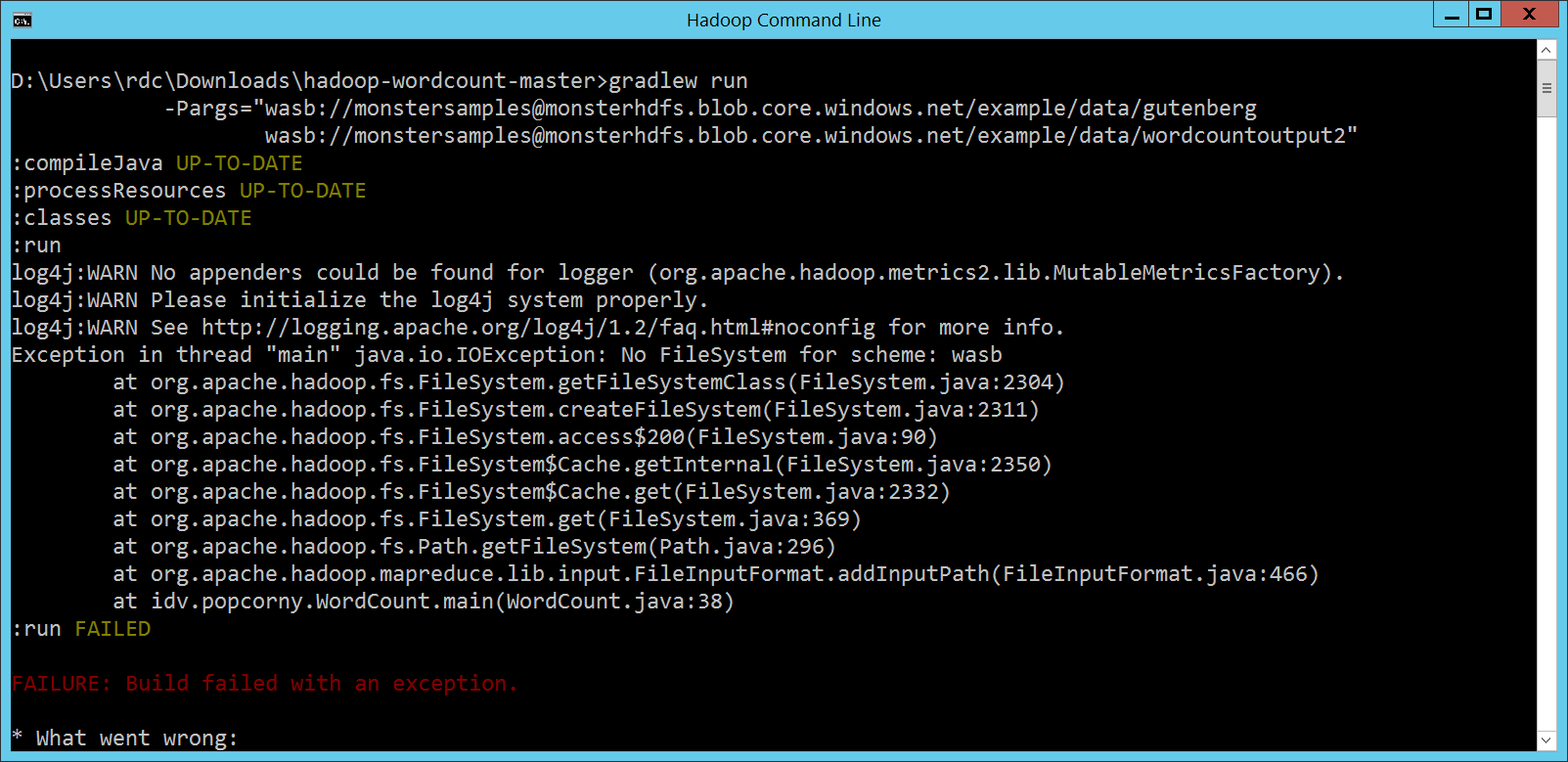
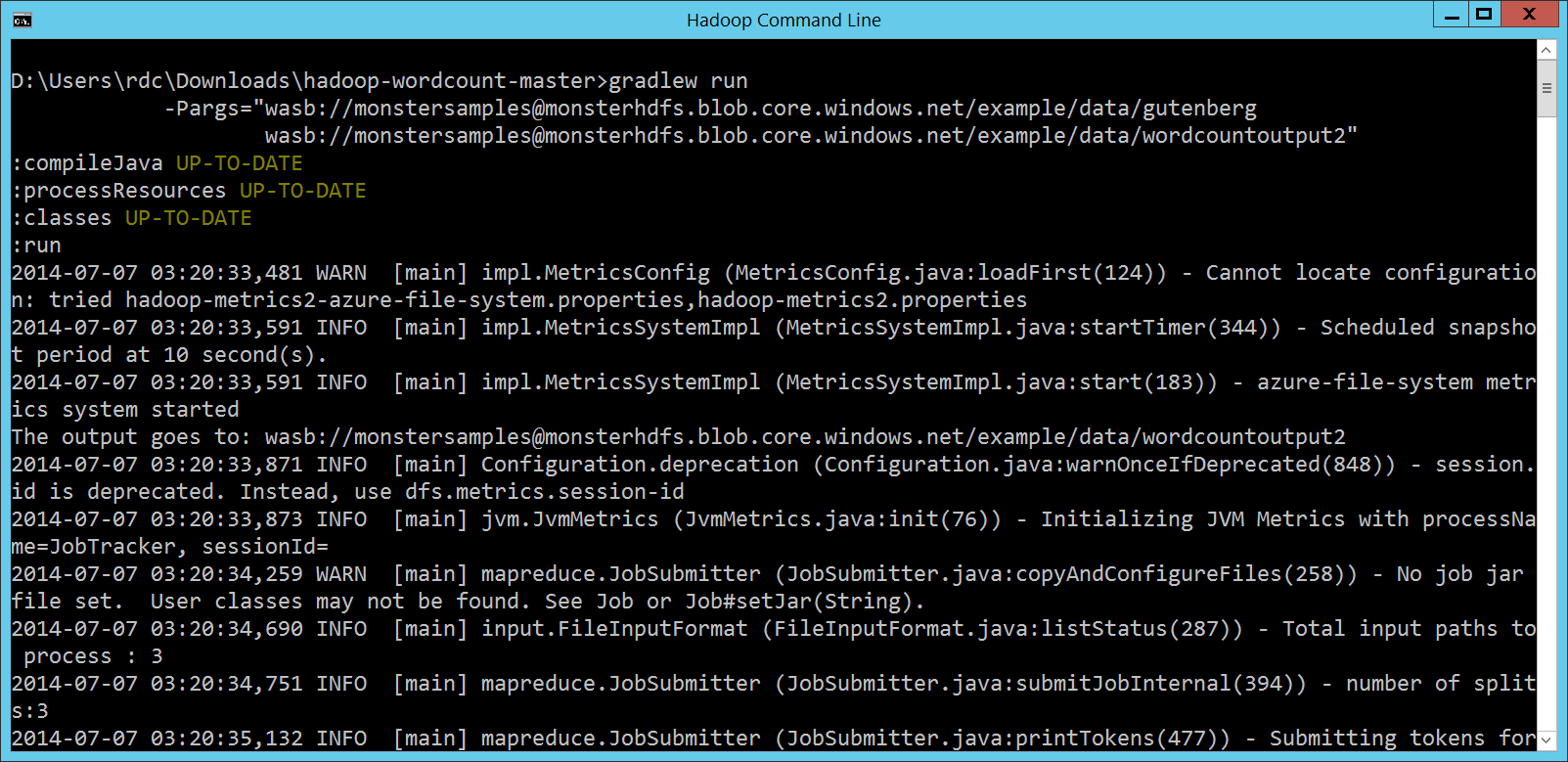
完整版的指令呢: gradlew run -Pargs="wasb://[email protected]/example/data/gutenberg wasb://[email protected]/example/data/wordcountoutput2"
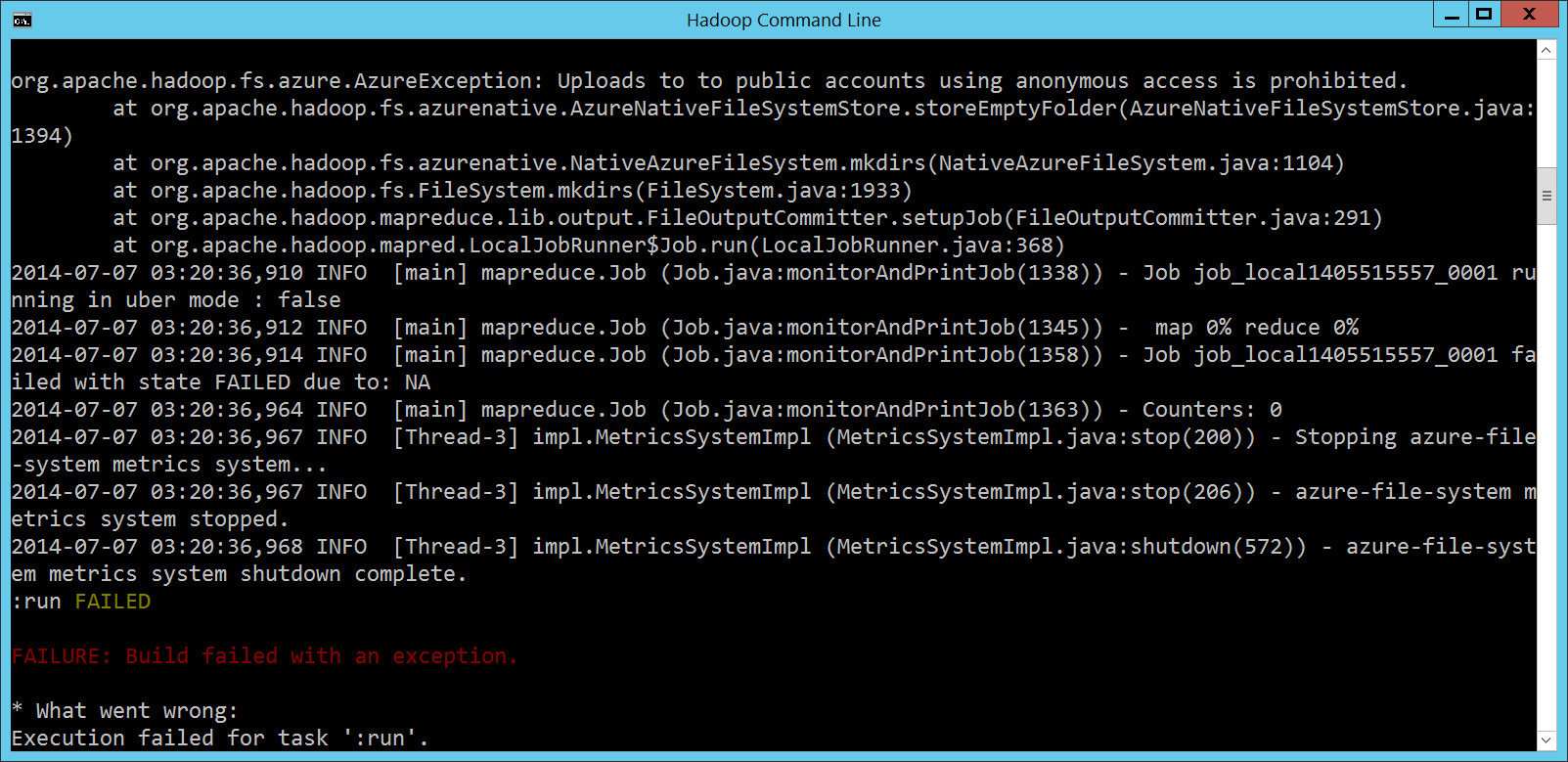
一樣不行,但是會給更多的提示訊息: org.apache.hadoop.fs.azure.AzureException: Uploads to to public accounts using anonymous access is prohibited.
at org.apache.hadoop.fs.azurenative.AzureNativeFileSystemStore.storeEmptyFolder(AzureNativeFileSystemStore.java:1394)
at org.apache.hadoop.fs.azurenative.NativeAzureFileSystem.mkdirs(NativeAzureFileSystem.java:1104)
at org.apache.hadoop.fs.FileSystem.mkdirs(FileSystem.java:1933)
at org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter.setupJob(FileOutputCommitter.java:291)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:368)
在「MapReduce 程式第 1 次的執行方式」那一段,我們曾經提到, 不過,這個雷比較像是 Azure Blob Storage 的 HDFS Wrapper 沒有處理好。同樣的 MapReduce 程式,如果 Submit 到 Hortonworks Sandbox 裡頭,透過同樣的 Gradle 指令寫法去執行的話: gradlew run -Pargs="hdfs://sandbox.hortonworks.com:8020/example/data/gutenberg
hdfs://sandbox.hortonworks.com:8020/example/data/wordcountoutput2"
是可以順利執行的。 MapReduce 程式第 4 次的執行方式HDInsight 的 Feature 不是我們瞬間可以解決的,那該怎麼辦呢? 反正跳過 上一篇文章最後的作法,其實就是比較醜的解法:
但是,有沒有辦法透過 Gradle,把這兩個步驟合而為一呢? 有的:自己寫一個 Gradle Task,把這兩件事包在一起。 apply plugin: 'java'
apply plugin: 'eclipse'
apply plugin: 'application'
mainClassName = "idv.popcorny.WordCount"
repositories {
mavenCentral();
}
jar {
manifest {
attributes 'Main-Class': "$mainClassName"
}
}
dependencies {
compile 'org.apache.hadoop:hadoop-client:2.3.0'
}
task hadoop(dependsOn: jar, type: Exec) {
if (System.properties['os.name'].toLowerCase().contains('windows')) {
project.ext.HADOOP_HOME = "$System.env.HADOOP_HOME".replaceAll('\\\\', '/')
project.ext.HADOOP_CMD = HADOOP_HOME + '/bin/hadoop.cmd'
commandLine 'cmd', '/c', HADOOP_CMD, 'jar', "$jar.archivePath"
}
else {
project.ext.HADOOP_HOME = "/usr/lib/hadoop"
project.ext.HADOOP_CMD = HADOOP_HOME + '/bin/hadoop'
commandLine HADOOP_CMD, 'jar', "$jar.archivePath"
}
if (project.hasProperty('args')) {
args project.args.split('\\s+')
args.each { commandLine.push(it) }
}
standardOutput = new ByteArrayOutputStream()
project.ext.output = {
return standardOutput.toString()
}
}
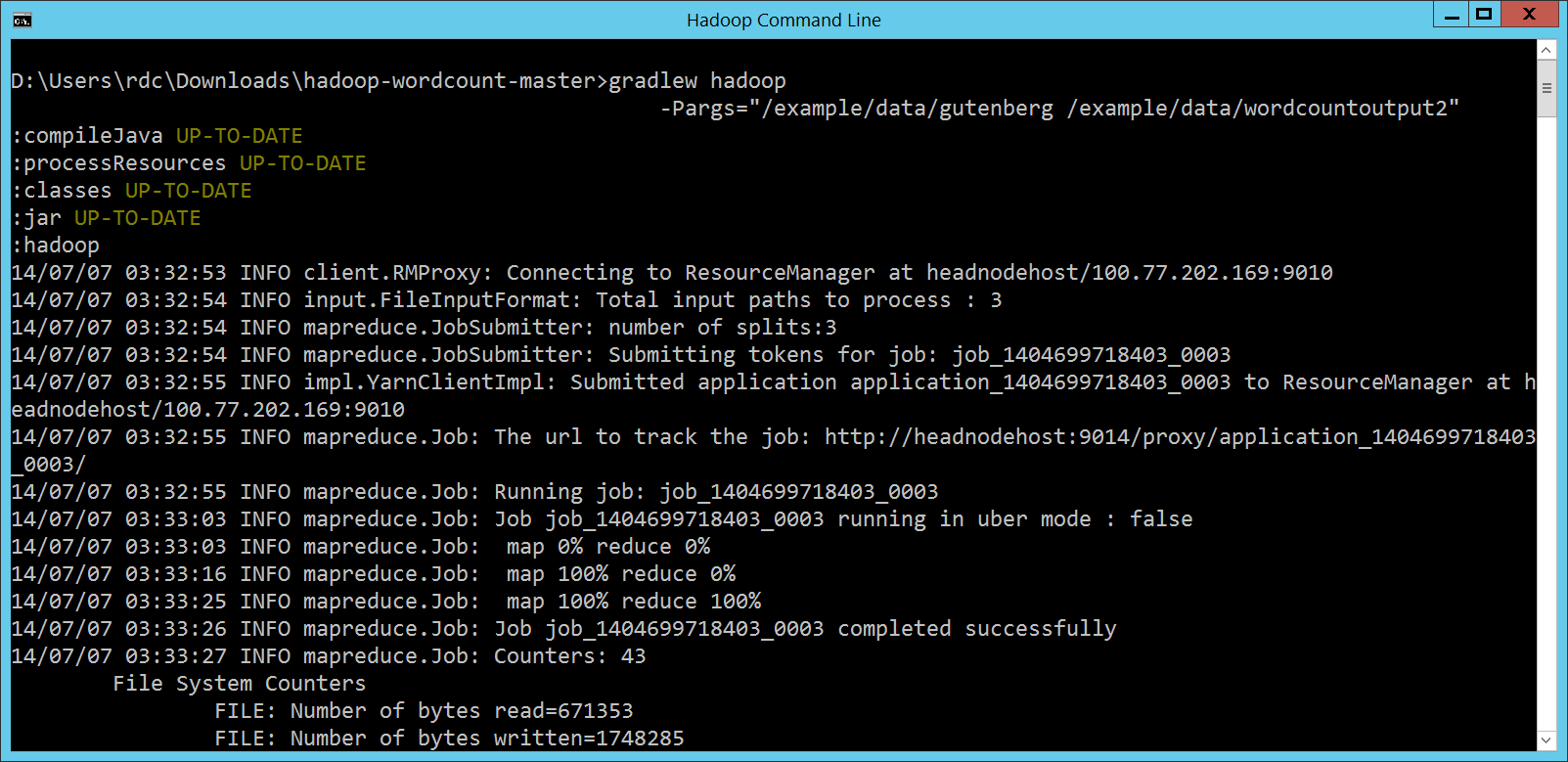
這時候,我們只要執行底下的 Gradle 指令: gradlew hadoop -Pargs="/example/data/gutenberg /example/data/wordcountoutput2" 就可以順利透過
|
相關文章
關於作者

目前從事教育訓練工作。自認為會的技術不多,但是學不會的也不多,最擅長把老闆交代的工作,以及找不到老師教的技術,想辦法變成自己的專長。